The help function tells us that the penguins are observed in the Palmer Archipelago, Antarctica during 2007-2009. So the population is all Adelie, Chinstrap, and Gentoo penguins in the Palmer Archipelago, Antarctica during the years 2007-2009. Is it reasonable to believe that this population is representative of the current penguin population? If we believe that it is, i.e. that the measurements made between 2007 and 2009 are still valid today, we can use our dataset to say something about the population today.
library(tidyverse)recreate_valjarbarometern <-function(valjarbarometern_aggregate, n){# Calculate number of observations of each party obs_per_party <-round(n * valjarbarometern_aggregate$percentage /100)# Create a list of party observations party_observations <-mapply(rep, valjarbarometern_aggregate$party, obs_per_party)# Flatten the list into a single vector sample_data <-unlist(party_observations)# Create a data frame with the samples valjarbarometern <-tibble(party = sample_data)return(valjarbarometern)}# Number of people in surveyn =3072parties <-c("V", "S", "MP", "C", "L", "KD", "M", "SD", "Other")# Aggregated samplevaljarbarometern_aggregate <-tibble(party =factor(parties, levels = parties), # Using levels to preserve orderpercentage =c(7.6, 37.6, 4.3, 3.9, 3, 3.1, 19, 19.7, 1.7))valjarbarometern <-recreate_valjarbarometern( valjarbarometern_aggregate, n)
17.2.1 Exercise 1
We simply replace MP with C:
\(H_0\): The proportion of people who would vote for MP is smaller than 0.04.
\(H_a\): The proportion of people who would vote for MP is larger than 0.04.
17.2.2 Exercise 2
We do the test for the C party instead.
n_participants <-3072# Number of participants in surveyn_c_voters <- valjarbarometern |># Number of participants who answered Cfilter(party =="C") |>summarize(n =n()) |>pull(n)p_h0 <-0.04# Our null hypothesis# Conducting hypothesis test of proportionsprop.test(n_c_voters, n_participants, p_h0, alternative ="less")
1-sample proportions test with continuity correction
data: n_c_voters out of n_participants, null probability p_h0
X-squared = 0.048018, df = 1, p-value = 0.4133
alternative hypothesis: true p is less than 0.04
95 percent confidence interval:
0.0000000 0.0454036
sample estimates:
p
0.0390625
We can see that the result is not statistically significant at significance level 0.05.
17.2.3 Exercise 3
We try one of the parties with the lowest percentage, KD.
# Note: L would also be below 4% with statistical significancen_participants <-3072# Number of participants in surveyn_kd_voters <- valjarbarometern |># Number of participants who answered KDfilter(party =="KD") |>summarize(n =n()) |>pull(n)p_h0 <-0.04# Our null hypothesis# Conducting hypothesis test of proportionsprop.test(n_kd_voters, n_participants, p_h0, alternative ="less")
1-sample proportions test with continuity correction
data: n_kd_voters out of n_participants, null probability p_h0
X-squared = 6.355, df = 1, p-value = 0.005853
alternative hypothesis: true p is less than 0.04
95 percent confidence interval:
0.0000000 0.0366646
sample estimates:
p
0.03092448
We see that the \(p\)-value is below 0.05, so the result is statistically significant at significance level 0.05.
17.3 Hypothesis test (mean)
17.3.1 Exercise 1
We write down the hypotheses with the population explicit:
\(H_0\): The mean flipper length of all penguins in the Palmer Archipelago during 2007-2009 was 200 mm.
\(H_a\): The mean flipper length of all penguins in the Palmer Archipelago during 2007-2009 was greater than 200 mm.
We then perform our t-test.
library(palmerpenguins)t.test(penguins$flipper_length_mm, mu =200, alternative ="greater")
One Sample t-test
data: penguins$flipper_length_mm
t = 1.2036, df = 341, p-value = 0.1148
alternative hypothesis: true mean is greater than 200
95 percent confidence interval:
199.6611 Inf
sample estimates:
mean of x
200.9152
Our test shows that we do not have evidence in the data that the mean flipper length of all penguins in the Palmer Archipelago during 2007-2009 was not greater than 200 mm at significance level 0.05.
17.3.2 Exercise 2
We first formulate our hypothesis, here we only do it for the test of flipper length between Gentoo and Chinstrap penguins.
\(H_0\): Gentoo and Chinstrap penguins have the same flipper length.
\(H_a\): Gentoo and Chinstrap penguins do not have the same flipper length.
Welch Two Sample t-test
data: gentoo_flipper_length and chinstrap_flipper_length
t = 20.463, df = 127.61, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
19.29770 23.42923
sample estimates:
mean of x mean of y
217.1870 195.8235
Welch Two Sample t-test
data: gentoo_flipper_length and adelie_flipper_length
t = 34.445, df = 261.75, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
25.67652 28.79018
sample estimates:
mean of x mean of y
217.1870 189.9536
Welch Two Sample t-test
data: chinstrap_flipper_length and adelie_flipper_length
t = 5.7804, df = 119.68, p-value = 6.049e-08
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
3.859244 7.880530
sample estimates:
mean of x mean of y
195.8235 189.9536
We have evidence that the flipper lengths are different between all species of penguins at significance level 0.05. Flipper length seem to be a useful variable to distinguish between different penguin species.
17.3.3 Exercise 3
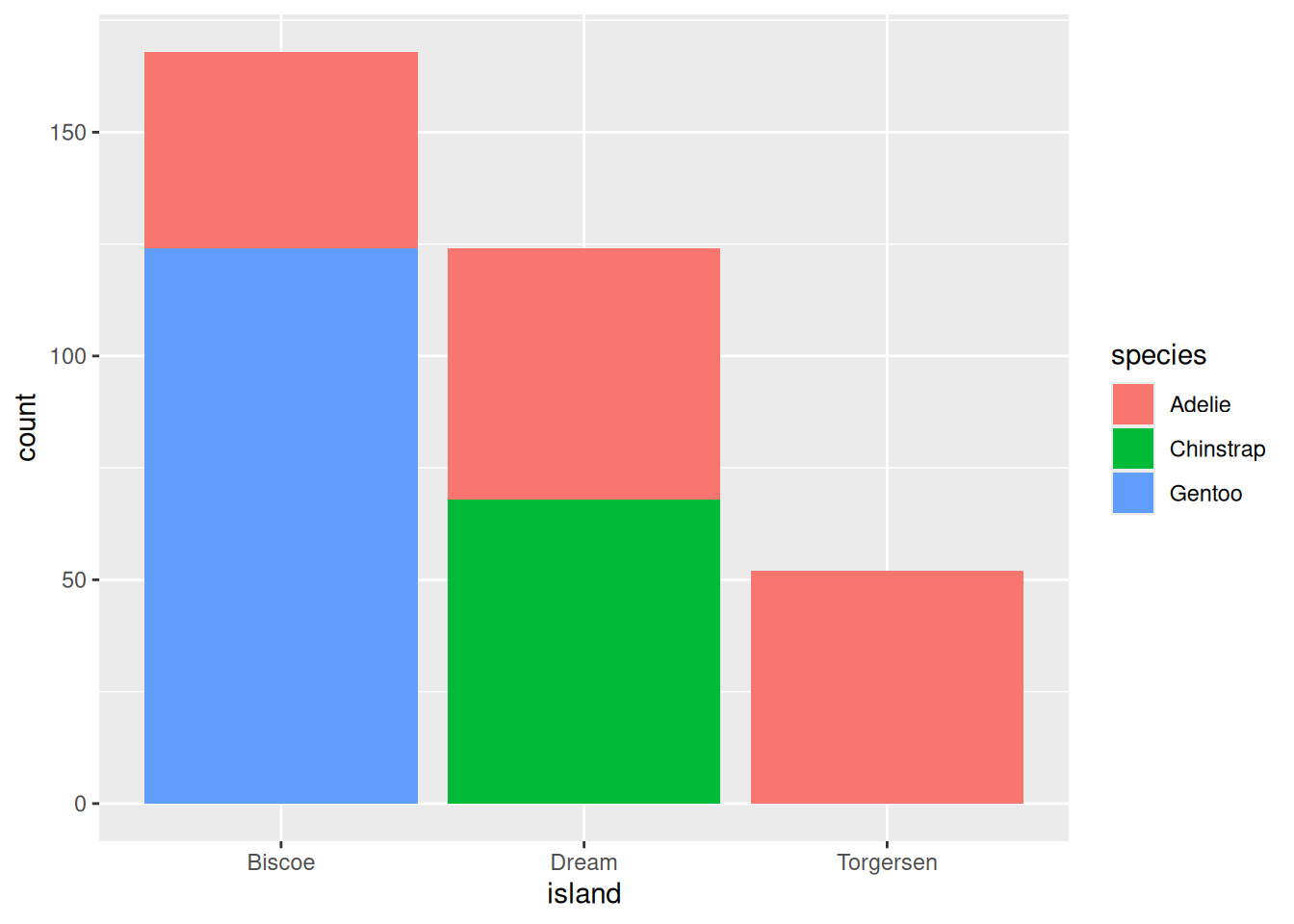
We start by visualizing using a bar chart.
penguins |>ggplot(aes(x = island, fill = species)) +geom_bar()
We see that there are a few more Chinstrap penguins than Adelie, but is the difference significant? We first formulate the hypotheses:
\(H_0\): The proportion of Chinstrap penguins at Dream island is 0.5.
\(H_a\): The proportion of Chinstrap penguins at Dream island is greater than 0.5.
Then we perform the proportions test using prop.test with the number of chinstrap penguins and the total number of penguins at Dream island, p = 0.5 (our null hypothesis), and alternative hypothesis “greater”.
n_total <- penguins |>filter(island =="Dream") |>summarize(n =n()) |>pull()n_chinstrap <- penguins |>filter(species =="Chinstrap"& island =="Dream") |>summarize(n =n()) |>pull()prop.test(n_chinstrap, n_total, p =0.5, alternative ="greater")
1-sample proportions test with continuity correction
data: n_chinstrap out of n_total, null probability 0.5
X-squared = 0.97581, df = 1, p-value = 0.1616
alternative hypothesis: true p is greater than 0.5
95 percent confidence interval:
0.4706263 1.0000000
sample estimates:
p
0.5483871
We see that the result is not significant. We do not have evidence in the data suggesting that there are more Chinstrap penguins than Adelie penguins at Dream island.
Can you think of any issue with this test and the sample? How can we be sure that the researchers didn’t try to observe the same amount of both species? It is important to ask these questions about data collection before you start your analysis.