Missing data is ubiquitous when working with real data. We typically (and should) represent missing values in our data by NA, which stands for “Not Available” or in other words, missing. The most obvious issue with missing data is that most of the algorithms we use rely on complete observations, observations without any missing values. Our algorithms simply will not produce a result if the data contains missing values. But this is not the only problem of missing data as, depending on why the data is missing, it may bias our inference and creating predictive models that do not perform as expected.
In this chapter we give a brief introduction to missing data and how we can handle it.
10.1 Why is data missing?
To illustrate how missing data can occur and in what ways we will rely on an artificial example with the palmerpenguins dataset. We first look at the summary of the dataset to remember the variables and see if it has any missing values.
species island bill_length_mm bill_depth_mm
Adelie :152 Biscoe :168 Min. :32.10 Min. :13.10
Chinstrap: 68 Dream :124 1st Qu.:39.23 1st Qu.:15.60
Gentoo :124 Torgersen: 52 Median :44.45 Median :17.30
Mean :43.92 Mean :17.15
3rd Qu.:48.50 3rd Qu.:18.70
Max. :59.60 Max. :21.50
NA's :2 NA's :2
flipper_length_mm body_mass_g sex year
Min. :172.0 Min. :2700 female:165 Min. :2007
1st Qu.:190.0 1st Qu.:3550 male :168 1st Qu.:2007
Median :197.0 Median :4050 NA's : 11 Median :2008
Mean :200.9 Mean :4202 Mean :2008
3rd Qu.:213.0 3rd Qu.:4750 3rd Qu.:2009
Max. :231.0 Max. :6300 Max. :2009
NA's :2 NA's :2
We note that there are a few missing values in the dataset and we will now try to understand different mechanisms that can cause these missing values, NAs. To understand how values become missing, we need to understand how the data was recorded. From the original reference of the study, the palmerpenguins dataset was collected by the following procedure
Each study season, Adélie penguin study nests (n = 30) were distributed equally between the three study islands, with 10 nests located on each island. Gentoo penguin study nests (n = 30) were all located on Biscoe Island, while chinstrap penguin study nests (n = 15) were all located on Dream Island (Fig. 1c). The reduced sample size for chinstraps was due to the overall smaller number of individuals breeding at rookeries on Dream Island. Each season, study nests, where pairs of adults were present, were individually marked and chosen before the onset of egg-laying, and consistently monitored. When study nests were found at the one-egg stage, both adults were captured to obtain blood samples used for molecular sexing and SI analyses, and measurements of structural size and body mass. At the time of capture, each adult penguin was quickly blood sampled (~1 ml) from the brachial vein using a sterile 3 ml syringe and heparinized infusion needle. Collected blood was stored in 1.5 ml micro-centrifuge tubes that were kept cool. In the field, a small amount of whole blood was smeared on clean filter paper stored in a 1.5 ml micro-centrifuge tube for molecular sexing. Measurements of culmen length and depth (using dial calipers $$60.1 mm), right flipper (using a ruler 61 mm), and body mass (using 5 kg \(\pm\) 625 g or 10 kg \(\pm\) 650 g Pesola spring scales and a weigh bag) were obtained to quantify body size variation. After handling, individuals at study nests were further monitored to ensure the pair reached clutch completion, i.e., two eggs.
Now that we have information about how the data was collected we can start to think about reasons for missing values. But first we need to understand more generally how values can become missing. Missing values are usually categorized into three different patterns: Missing Completely At Random (MCAR), Missing At Random (MAR), and Not Missing At Random (NMAR). In this course we will only focus on the first form, MCAR, and assume that it holds. For those who are interested there is a short section at the end of this chapter that introduces the other types of missingess and methods to deal with them.
10.2 Handling missing values when MCAR
When values are “missing completely at random” there is no systematic explanation for why a specific value is missing. In our example this may happen if for example the blood sample of a penguin was lost, resulting in a missing value in the sex variable, or if one of the researchers would spill coffee on the noted values, ruining the paper. These events are “completely random” and does not depend on characteristics of the penguins themselves. In this case we can use intuitive methods to handle the missing values since the missing values are not introducing any bias in our data.
10.2.1 Complete case analysis
If the missing values are believed to be missing completely at random (MCAR) and there are only a few missing values we may use the observations that are complete in our dataset. This is called complete case analysis and we can achieve it using the drop_na function
penguins_complete <- penguins |>drop_na()
10.2.2 Mean imputation
If we have several missing values such that we have to drop a substantial part of our dataset but we still believe that the values are MCAR we may impute the values. When we impute the values of a variable we use information from our data to replace the missing value, to impute it. A simple method of imputation is single value imputation where all missing values for one variable is replaced with the same value. If the variable is continuous, a natural and common value to use is the mean of the variable, called mean imputation. We can impute the missing flipper lengths in the penguins data using mean imputation with the mutate and replace_na functions from dplyr.
mean_flipper_length <-mean(penguins$flipper_length_mm, na.rm =TRUE)penguins_imputed <- penguins |># Flipper length is integer, so we need to convert it to numericmutate(flipper_length_mm =as.numeric(flipper_length_mm)) |>mutate(flipper_length_mm =replace_na(flipper_length_mm, mean_flipper_length))penguins_imputed |>summary()
species island bill_length_mm bill_depth_mm
Adelie :152 Biscoe :168 Min. :32.10 Min. :13.10
Chinstrap: 68 Dream :124 1st Qu.:39.23 1st Qu.:15.60
Gentoo :124 Torgersen: 52 Median :44.45 Median :17.30
Mean :43.92 Mean :17.15
3rd Qu.:48.50 3rd Qu.:18.70
Max. :59.60 Max. :21.50
NA's :2 NA's :2
flipper_length_mm body_mass_g sex year
Min. :172.0 Min. :2700 female:165 Min. :2007
1st Qu.:190.0 1st Qu.:3550 male :168 1st Qu.:2007
Median :197.0 Median :4050 NA's : 11 Median :2008
Mean :200.9 Mean :4202 Mean :2008
3rd Qu.:213.0 3rd Qu.:4750 3rd Qu.:2009
Max. :231.0 Max. :6300 Max. :2009
NA's :2
We see that the flipper length variable now has no missing values, while keeping the same mean value.
10.2.3 Mode imputation
If our variable is categorical we cannot use mean imputation. Instead, we can use the mode, the most common value, to impute the missing values. We can impute any missing values of the sex variable using mode imputation using the replace_na function from dplyr.
species island bill_length_mm bill_depth_mm
Adelie :152 Biscoe :168 Min. :32.10 Min. :13.10
Chinstrap: 68 Dream :124 1st Qu.:39.23 1st Qu.:15.60
Gentoo :124 Torgersen: 52 Median :44.45 Median :17.30
Mean :43.92 Mean :17.15
3rd Qu.:48.50 3rd Qu.:18.70
Max. :59.60 Max. :21.50
NA's :2 NA's :2
flipper_length_mm body_mass_g sex year
Min. :172.0 Min. :2700 female:165 Min. :2007
1st Qu.:190.0 1st Qu.:3550 male :179 1st Qu.:2007
Median :197.0 Median :4050 Median :2008
Mean :200.9 Mean :4202 Mean :2008
3rd Qu.:213.0 3rd Qu.:4750 3rd Qu.:2009
Max. :231.0 Max. :6300 Max. :2009
NA's :2
We see that the sex variable now has no missing values. In this case, there was a small difference between females and males in the sex distribution and using the mode might not have been the best option. For more advanced methods of imputation, see the advanced section at the end of this chapter.
10.3 Other types of missing values and advanced imputation
In this section we introduce the other types of missing values. This is beyond the scope of the course, but may be of interest to some students.
10.3.1 Missing at random (MAR)
Values that are “missing at random” are missing because of some reason that is recorded in the data. In our example, the penguins body weight is measured by using a scale and a weigh bag. Maybe penguins with longer flippers are harder to fit in the weigh bag, making the researchers more prone to failing weighing penguins with long flippers. Or maybe female penguins are harder to gather a blood sample from due to smaller brachial veins. This results in a missingness patterns in the body_weight_g and sex variables that can to some extent be explained by the flipper length or sex of the penguin. Thus the missingness pattern depends on our data and we can use it to better make educated guesses while imputing.
10.3.2 Not missing at random (MNAR)
Not missing at random happens when values are systematically missing, but we have not observed the reason for why the specific values are missing. For example, if some of the penguins are of poor health the researchers may choose to not weigh the penguin to avoid the extra stress of being put in the weigh bag. This results in missing values of body weight but there is no record of penguin health in the data that can help us explain the missingness.
This is the hardest type of missing values to handle as we have no way of repairing it using the available data and it may influence our inference and prediction. If we suspect this type of missing values the best option is to collect more data, compensating for the missingness in the original data.
10.3.3 Regression imputation
If data is MAR we can use our dataset to make more informed imputations. One way that may be appealing after learning about linear and logistic regression is to use this methods to assign values instead, performing regression imputation. We illustrate a simple form of regression imputation to make a more educated guess for the missing values of the sex variable that we imputed by the mode earlier. First, we make a logistic regression model to predict the sex of the penguins based on the other variables in the dataset.
sex_model <- penguins |>glm(formula = sex ~ ., family = binomial)
Lets select only the significant variables (0.05) using backward selection to have a simpler model. This can be useful if we have more missing values in other columns, which would prevent us from using these columns for imputation. Once we have our model with only significant variables we can use it to predict the sex of the penguins with missing values.
# Fit new model after backward selectionsex_model <- penguins |>glm(formula = sex ~ . - island - year - flipper_length_mm, family = binomial)# Select penguins with missing sexpenguins_missing_sex <- penguins |>filter(is.na(sex))# Predict sex probabilitypredicted_sex_probability <-predict(sex_model, newdata = penguins_missing_sex, type ="response")# Convert probabilities to factor levelspredicted_sex <- (predicted_sex_probability >0.5) |>ifelse("male", "female") |>factor(levels =levels(penguins$sex))predicted_sex
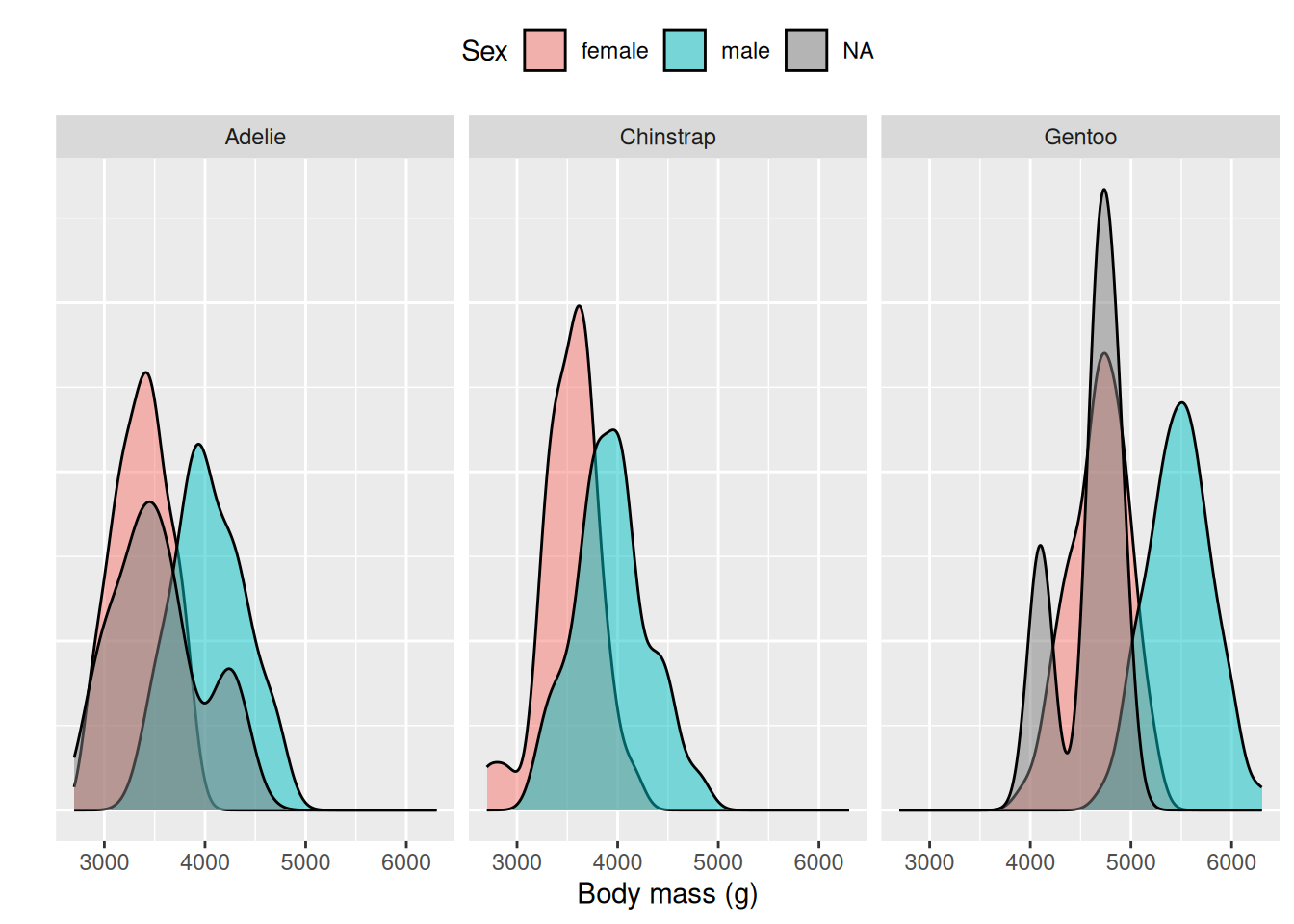
We see that one penguin still has a missing value. This observation has missing values in all variables in our sex_model except species. Interestingly our model predict most penguins to be female. We can be fairly confident in our predictions as body measurements and species should make it quite easy to differentiate between the sexes of the penguins, as illustrated by the following density plots of body mass, also showing the missing values.
Code
# Plot the distributions of the body weight and color by sex and facet by speciespenguins |>ggplot(aes(x = body_mass_g, fill = sex)) +geom_density(alpha =0.5) +facet_wrap(~species) +theme(axis.text.y =element_blank(), # Remove y-axis textaxis.ticks.y =element_blank()) +# Remove y-axis tickslabs(x ="Body mass (g)",y ="",fill ="Sex") +theme(legend.position ="top") +guides(color =guide_legend(nrow =1))
Regression imputation is a useful tool that you already know how to do if you have completed the regression chapters.
10.3.4 Multiple imputation
Multiple imputation is the most popular imputation. It consists of sampling from the distribution of observed values to create new dataset. It is a conceptually more difficult method, but if you are interested you can have a look at the mice package in R.
10.4 Summary
In this chapter we have looked at missing values, types of missingness mechanisms, and how to impute missing values when values are MCAR and MAR.