This chapter aims to cover basic statistical concepts which are crucial in data analysis. It will cover variables and their distributions and how descriptive statistics can tell us more about them. We will be using R and visualization techniques throughout the chapter to illustrate. We don’t expect you to understand all the code in this chapter, especially for the visualizations, but it can be useful later in the course as a resource. Therefore some of the code is hidden by default, but you can press the line that says Code to see the code!
The examples will be using the palmerpenguins dataset (short penguins) which you can install using
This chapter covers numerical and categorical variables and their (empirical) distributions, descriptive statistics (mean, median, standard deviation, percentiles), and correlation between two numerical variables.
2.2 Variables
In data analysis we encounter various types of variables. These variables store information about different objects or quantities, like in the penguins dataset where variables represent different species of penguins and their flipper lengths. For each observed penguin we have a value of each variable. Variables can assume different types which dictate the kind of analysis that can be performed based on them. Understanding the different variable types and being able to classify variables as a certain type is very important to perform correct and sound analysis. We will look at two types of variables in this introduction: numerical and categorical variables.
2.2.1 Numerical
Variables that represents numbers. They can come in two forms:
Integer: Represents discrete numerical values, e.g., number of items in a cart or a year. A rule of thumb is that if you can count it, then it is an integer.
Continuous: Represents continuous numerical values, e.g., the weight of an item or a distance.
To be able to handle variables correctly, each type is represented in R, but sometimes under a different name. An integer is called integer in R, and a continuous variable is called a numeric or double.
2.2.2 Categorical
Represents a finite set of categories, e.g., types of fruits. What sets categorical variables apart from numerical variables are that there is no natural ordering between the different values: an apple is not worth more than a pear! Sometimes we can have ordered categorical variables, these have some internal order, but instead there is no natural distance between the values. You can think of customer satisfaction: a customer may be dissatisfied, neutral, or satisfied. Would you say that the distance between dissatisfied and satisfied is twice the distance between dissatisfied and neutral? Even if you could come up with some way of thinking about a distance, there will not be a natural distance that everyone can agree upon. Instead we can only order the variable into ordered categories.
The most simple case of a categorical variable is a binary variable. It consists only of two categories, like the variable sex in the penguins dataset that you will soon get familiar with.
In R, a categorical variable is called factor, or if it is ordered ordered factor.
2.2.3 Variables in penguins
Now we will take a look at the penguins dataset
Variable
Description
Variable Type
In R
species
Penguin species (Adélie, Chinstrap, Gentoo)
Categorical
factor
island
Island in Palmer Archipelago, Antarctica (Biscoe, Dream, Torgersen)
Categorical
factor
bill_length_mm
Bill length in millimeters
Continuous
numeric
bill_depth_mm
Bill depth in millimeters
Continuous
numeric
flipper_length_mm
Flipper length in millimeters
Integer
integer
body_mass_g
Body mass in grams
Integer
integer
sex
Penguin sex (female, male)
Categorical
factor
year
Study year (2007, 2008, 2009)
Integer
integer
We see that the dataset contains integer, continuous, and categorical variables, but some variables doesn’t seem to add up with what we would expect. The variables flipper_length_mm and body_mass_g are stored as integers but should be continuous, as flipper lengths and body mass can assume any continuous value. Sometimes this happens when variables are recorded using rounded numbers. Most of the time the difference between integer and numeric doesn’t affect our analysis since R is smart to figure out the encoding by itself, but for other variable types it is important to code them correctly. We may recode the variables using functions such as as.integer to code something as an integer, as.numeric to continuous, or as.factor to categorical. Recoding is especially important if a categorical variable is stored as a integer or numeric instead of a factor, or vice-versa, as it will change what analysis you can do with the variable.
Now that we know the variables in our dataset we can look at them in R by using the glimpse function.
Now we can see the variables: in the first column we see the variable name, in the second an abbreviation of the variable type, and then observed values. The first penguin in our dataset has the values Adelie species, observed on Torgersen, bill length of 39.1 mm, and so on. We can also see that some values are marked NA. These are missing values, where a measurement is missing. This is common in real data, and you will encounter it and have to deal with it many times.
Now that we have seen the different variable types and an example, we can start asking questions about how these variables behave. Which is the most common species in our data set? What is the average flipper length? These are all questions about the distributions of the variables.
2.2.4 Exercises
Use the summary function to learn more about the variables in the penguins dataset. How does the summary output differ for categorical and numerical variables? How many NA's are there for each variable (Hint: Look at the last line below each variable). Don’t worry if you don’t understand every detail of the output yet, just note the differences.
Run the code below to recode the variables flipper_length_mm and body_mass_g. Run the functions glimpse and summary on the penguins dataset to check that the variables have indeed changed.
Distributions describe how likely different values are for a variable. How are the values distributed? We have two types of distributions: discrete and continuous.
2.3.1 Discrete distributions
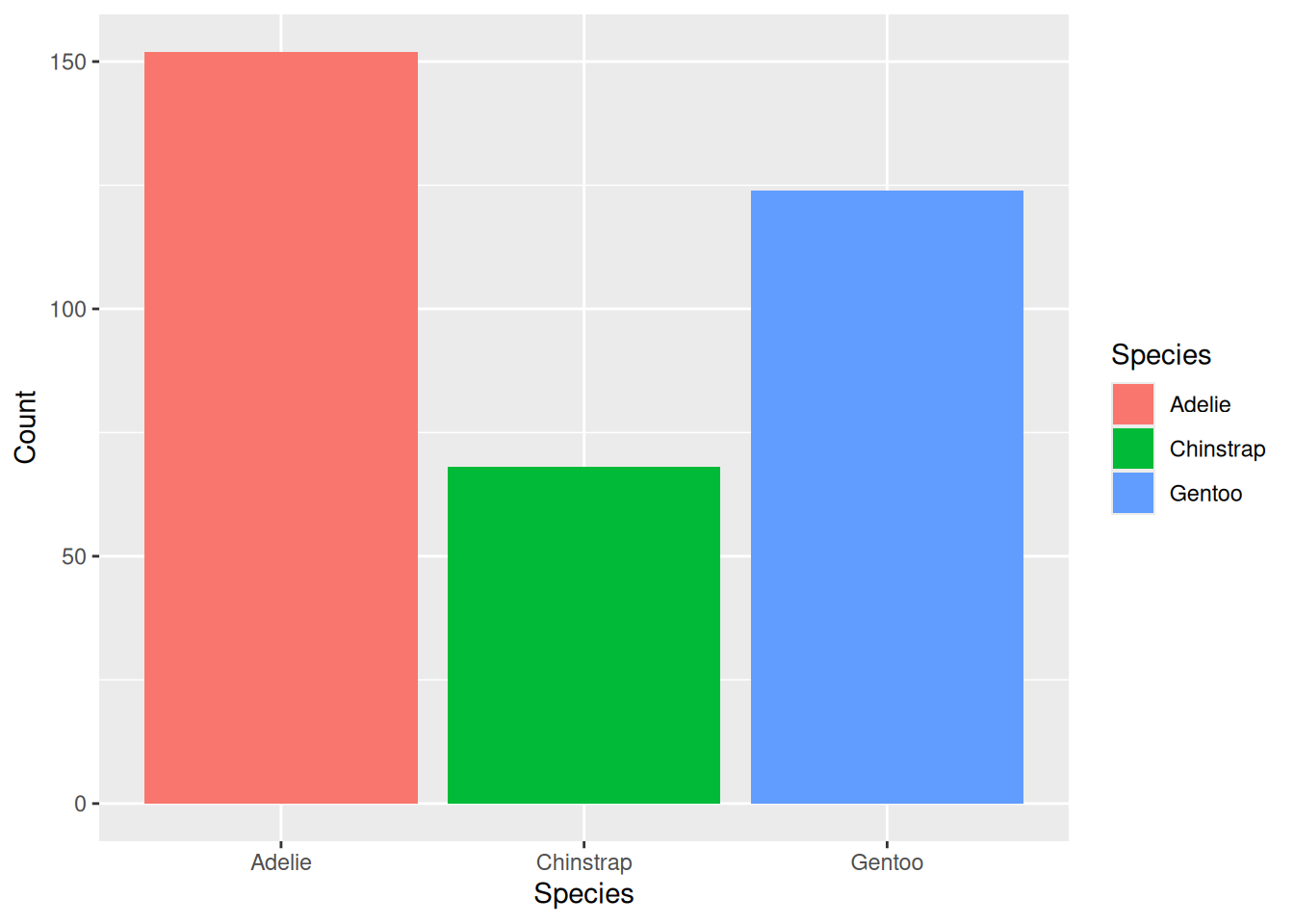
Discrete distributions deal with categorical variables. In the penguins dataset we have a several variables that have discrete distributions, one of them is species. We can visualize a discrete distribution using a bar chart:
In our bar chart we can see the different species that are observed in the dataset, i.e. what value the variable species can take, and how many of each species was observed, i.e. which values are more common. We see that the Adelie species is the most common in our dataset.
2.3.2 Continuous distributions
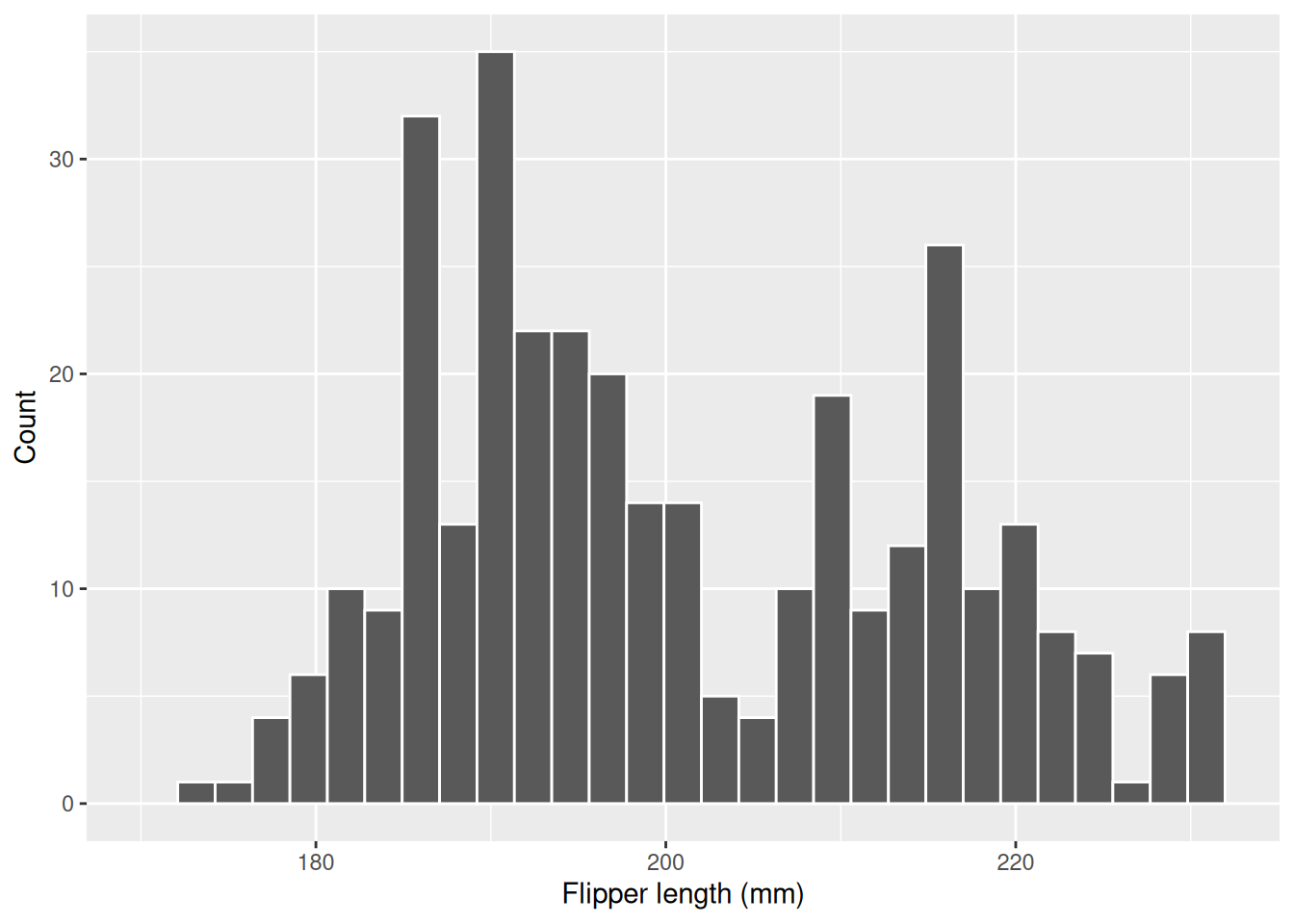
All variables representing measurements of the penguins bodies are continuous variables, like flipper_length_mm. To get an idea of how the flipper lengths are distributed in our data, we can use a histogram, as shown below. A histogram is a series of bars, where each bar represents a specific range of values, and the height of the bar shows the frequency or count of that value. That is, the more common it is for a flipper length to fall within a certain interval, the higher the bar.
In the histogram we can see that flipper lengths vary from around 170-230 mm and that flipper lengths around 190 mm and 215 mm seem common. But what is the average flipper length? And can we say something about the variation in flipper lengths? For this we can use descriptive statistics.
2.4 Descriptive statistics
Descriptive statistics tells us about a variable: the range of the variable, i.e. its minimum and maximum value, the average or the mean value, and the variation. The bar chart and histogram offers a qualitative way of asserting these values, but descriptive statistics gives us numbers and doesn’t rely on our own (subjective) observations.
Some of the most common descriptive statistics are
Counts: The number of observations of each variable in a category. For example the number of Adelie, Chinstrap, and Gentoo penguins in the penguins dataset. We already saw this in our bar chart in section Section 2.3.1.
Mean: The average value of a variable, counted by summing the value of each observation and dividing by the total number of observations. For example summing all the flipper lengths in penguins (the values) and dividing it by the total number of penguins observed in penguins (number of observations).
Median: The middle value after sorting a variable in increasing order, i.e. the value that is bigger than 50% of all the values of the variable. For example if you line up all the 344 penguins in penguins in order of flipper length, the median value is the value in between the 172nd and 173rd penguin, where 172 is 50% of the penguins.
Standard Deviation/Variance: Measures the deviation of data from its mean and tells us about how much a variable varies. For example the variation of flipper lengths within the Adelie penguins is smaller than the variation of the flipper lengths of all the penguins, as you will see later. Standard deviation and variance are important statistical concepts, but we will not spend too much time on them in this course.
Range, Quartiles, Quantiles, Percentiles: These help in understanding the spread and distribution of the data in different segments. The range is the minimum and maximum value, while quartiles, quantiles, and percentiles divide the data into proportions.
We will now take a look at the flipper lengths using these descriptive statistics.
2.4.1 Mean and median of flipper length
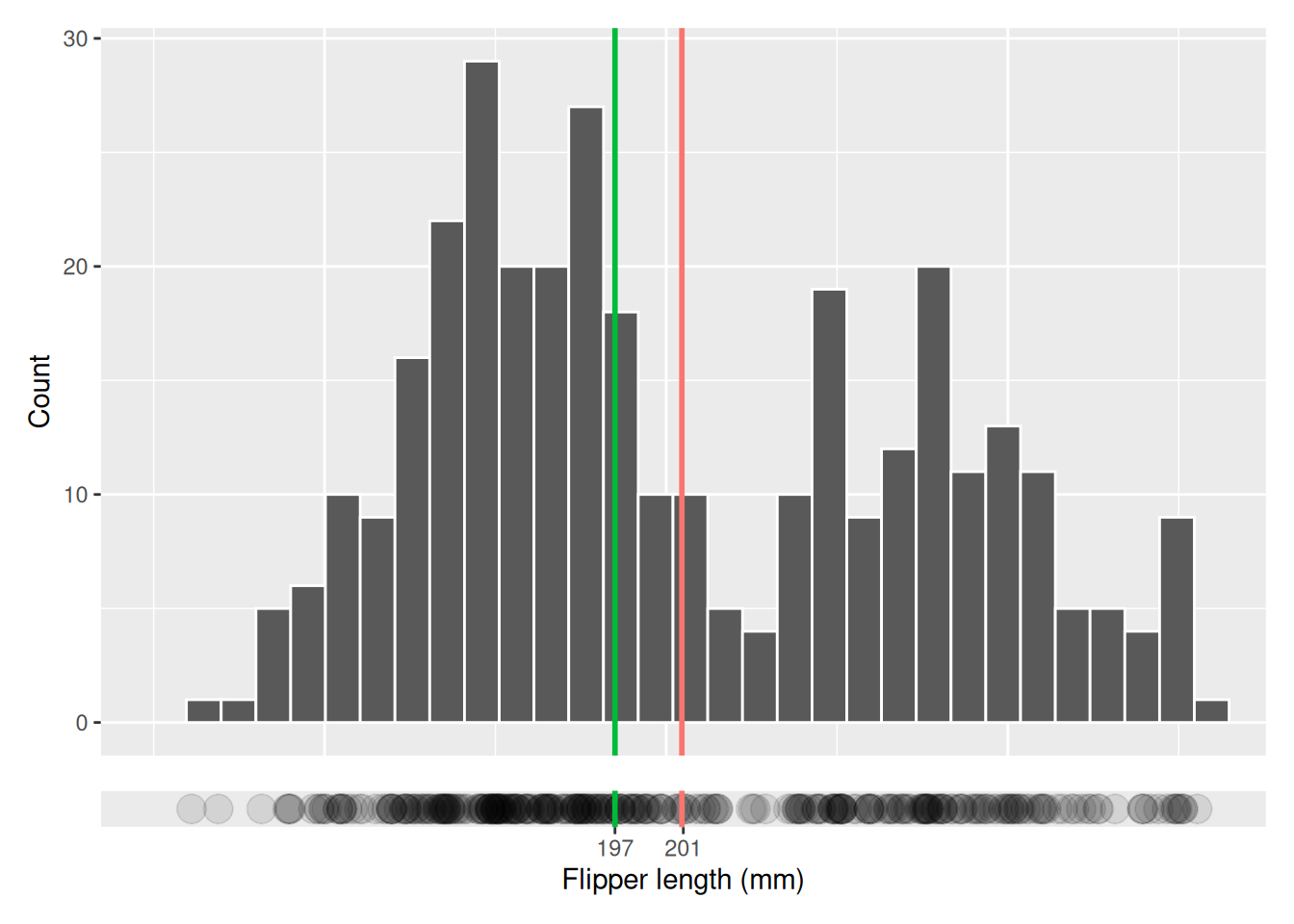
Both the mean and the median are measures of the center of the distribution. To calculate these values in R we use the mean and median functions. Note that here we use na.rm to handle the NAs, the missing values.
In this case we see that the mean and median is quite similar and both are a good estimation of the center of the distribution. Usually the mean is a good statistic to use, but there are two cases when the median is a better choice. If there are some observations that are very different to the majority of the observations, called outliers, the median may be the better choice and if the distribution is very skewed, where the distribution has a lot of very high or low values.
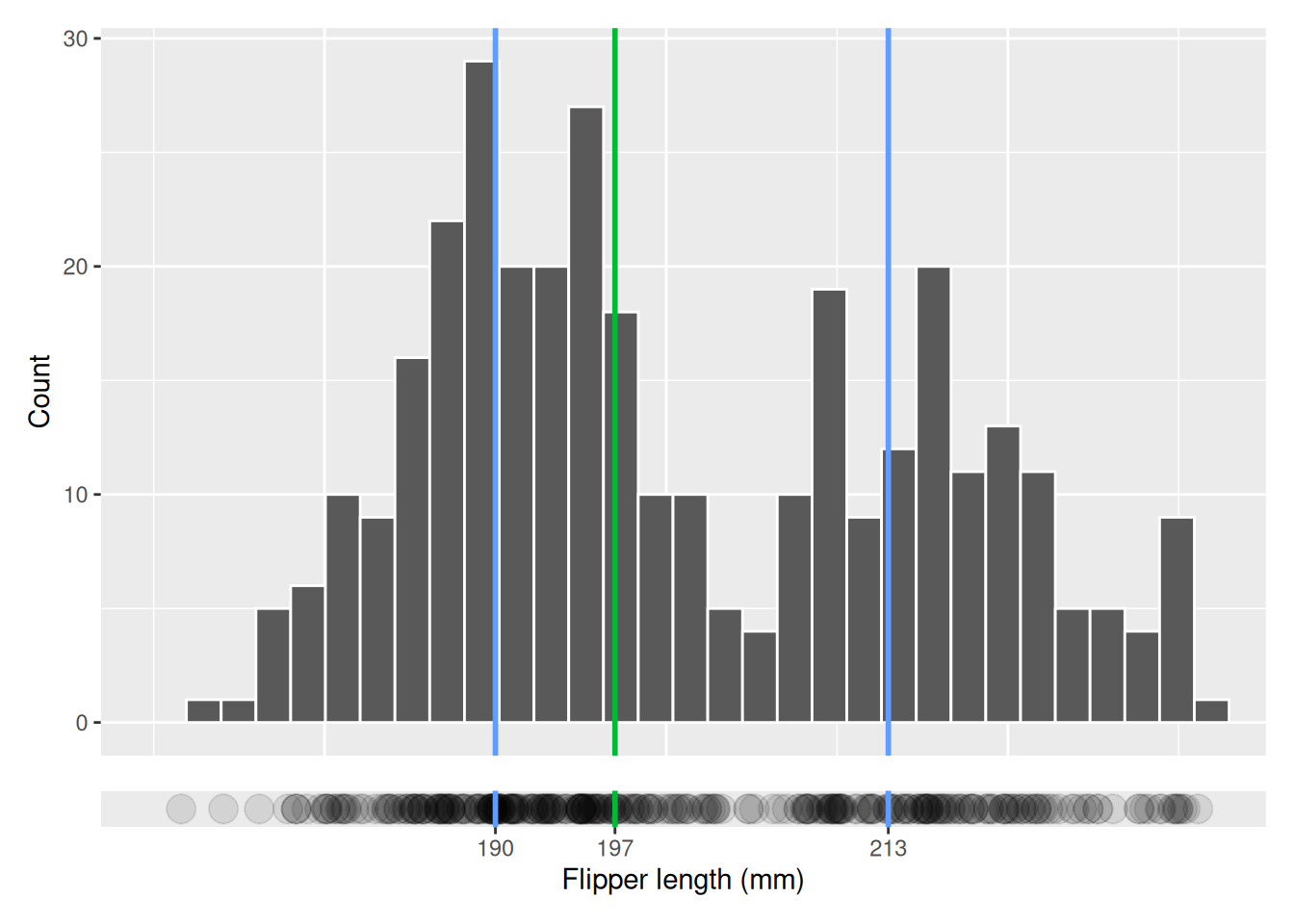
We can visualize the mean and median in our histogram by drawing vertical lines. In this visualization we have also added the individual observations as points below the histogram. Where there are many points, i.e. where there is less opacity, the count is higher.
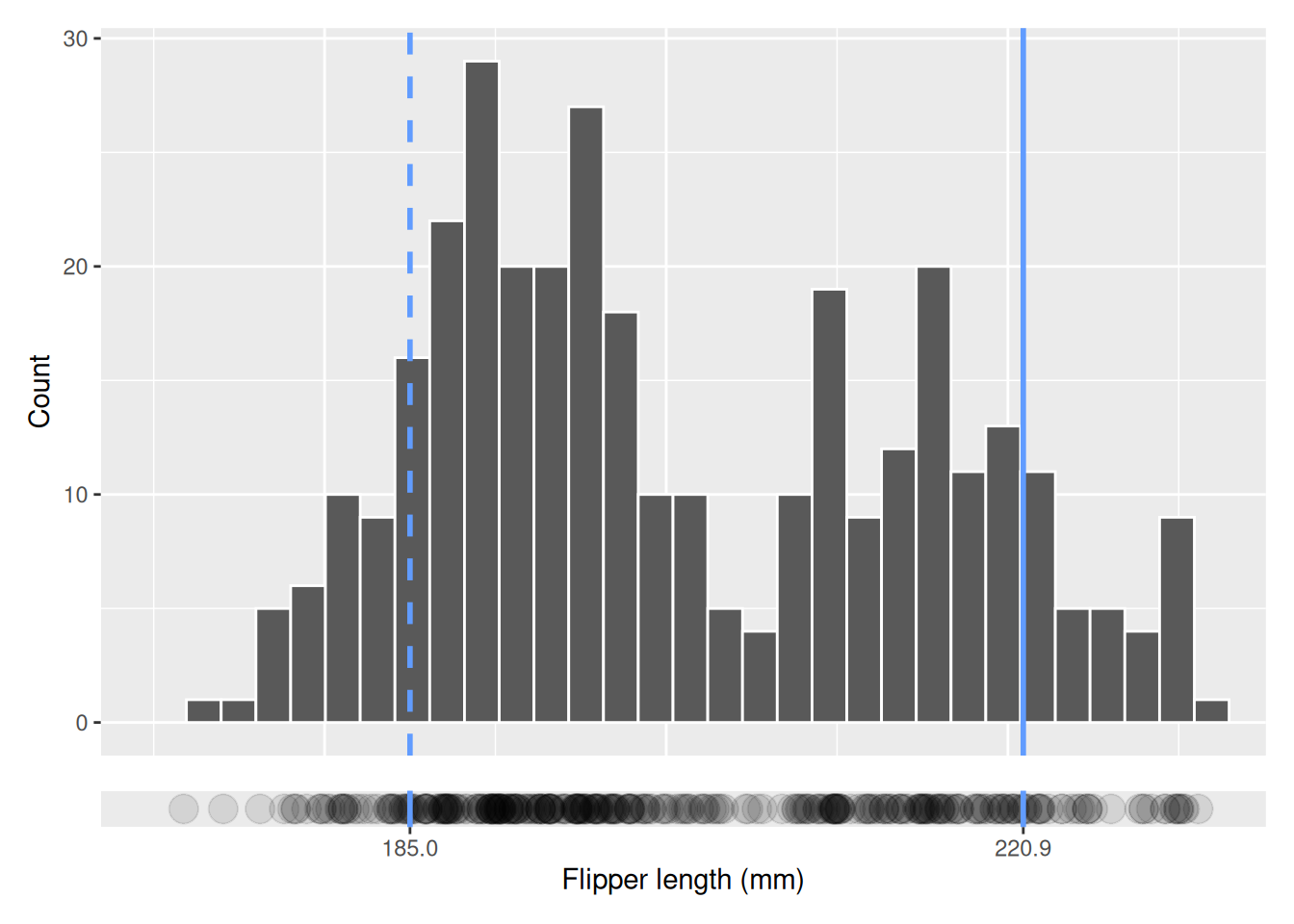
Percentiles and quartiles are a statistical measures used to describe the relative standing of a value within a data set. For example, if we were to order the penguins in our data based on flipper length, the 90th percentile is the flipper length of the penguin who has a longer flippers than 90% of penguins and 10th percentile is the flipper length of the penguin who has longer flippers than only 10% of penguins. We can visualize the 10th and 90th percentile in a histogram using blue, vertical lines where the 10th percentile is dashed.
We see that the 10th percentile is 185, i.e. that 10% of the penguins have flippers shorter than 185 mm, and likewise for the 90th percentile, 90% of the penguins have flippers shorter than 221 mm. We can calculate percentiles using the quantile function in R, specifying the percentile as a proportion, percentile / 100.
We see that the result agrees with what we observed in the histogram.
Quartiles are like percentiles, but they divide the data into 4 equally sized parts instead of a 100 parts (one for each percent). The first quartile is larger than 25% of values, the second is larger than 50% of the values and the third is larger than 75% of the values. Below we visualize the quartiles in a histogram, where the first and third quartiles are blue and the second quartile is green.
We visualize the second quartile in green because it is the same as the median, it is the value that is larger than half of all the values.
2.4.3 The summary function
The summary function is a very useful function to quickly get an overview of all the variables, their type, their descriptive statistics, and how many missing values there are, all with just one command. We take a look at the summary of the penguins dataset.
summary(penguins)
species island bill_length_mm bill_depth_mm
Adelie :152 Biscoe :168 Min. :32.10 Min. :13.10
Chinstrap: 68 Dream :124 1st Qu.:39.23 1st Qu.:15.60
Gentoo :124 Torgersen: 52 Median :44.45 Median :17.30
Mean :43.92 Mean :17.15
3rd Qu.:48.50 3rd Qu.:18.70
Max. :59.60 Max. :21.50
NA's :2 NA's :2
flipper_length_mm body_mass_g sex year
Min. :172.0 Min. :2700 female:165 Min. :2007
1st Qu.:190.0 1st Qu.:3550 male :168 1st Qu.:2007
Median :197.0 Median :4050 NA's : 11 Median :2008
Mean :200.9 Mean :4202 Mean :2008
3rd Qu.:213.0 3rd Qu.:4750 3rd Qu.:2009
Max. :231.0 Max. :6300 Max. :2009
NA's :2 NA's :2
We see that we get the counts for the categorical variables (discrete distributions) and the range (“Min.”, “Max.”), the first and third quartiles (“1st Qu.”, “3rd Qu.”), the mean and median, and the number of missing values (“NA’s”) fir the numerical variables (continuous distributions). The summary function is very good to use to get an idea about all the variables in a dataset.
2.4.4 Exercises
What happens if you run the mean function without na.rm = TRUE?
Try calculating the mean and median of some other variables in the penguins dataset. What happens if you try to calculate the mean of a factor?
Use the quantile function with the parameter prob = 0.5 for the variable body_mass_g to calculate the 50th percentile of the penguin body masses. Compare it with the output of the median function for the same variable.
Run the code below to show the summary of the variables in the diamonds dataset. Which variables are categorical vs. numerical? Are there any missing values?
library(tidyverse)summary(diamonds)
2.5 Relationships between variables
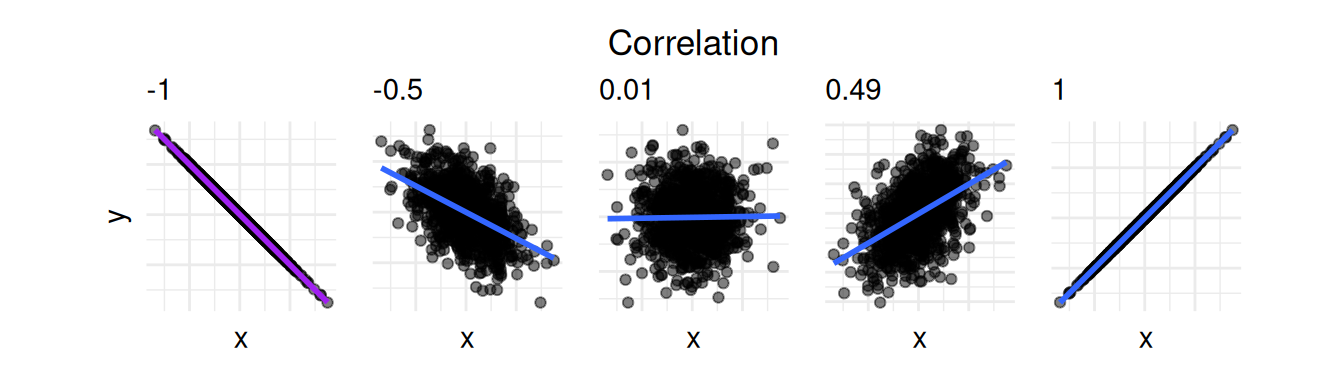
So far we have only worked with one variable at a time and we have seen how to study the variation of one variable, but often it is interesting to know about the correlation of two variables. Correlation tells us about how much two variables linearly correlate. If two variables are positively (negatively) correlated, large values of one variable often correspond to large (small) values of the other variable. Correlation is always a number between -1 (negative correlation) and 1 (positive correlation). 0 indicates that the variables are not correlated. The figure below shows the relationship between two variables and the correlation between them.
Code
library(patchwork)set.seed(42) # Setting a seed to get the same output every time.# Generating x and y variables based on different correlation scenariosN <-1000x <-rnorm(N)y1 <--x +rnorm(N, sd =0.01) # Correlation ~ -1y2 <--0.5* x +rnorm(N, sd =sqrt(0.75)) # Correlation ~ -0.5y3 <-rnorm(N) # Correlation ~ 0y4 <-0.5* x +rnorm(N, sd =sqrt(0.75)) # Correlation ~ 0.5y5 <- x +rnorm(N, sd =0.01) # Correlation ~ 1# Creating a data framecorr_df <-data.frame(x, y1, y2, y3, y4, y5)# Creating individual plots with titles and modified themesplot1 <-ggplot(data = corr_df, aes(x = x, y = y1)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", se = F, col ="purple") +theme_minimal() +labs(y ="y", subtitle =round(cor(corr_df$x, corr_df$y1), digits =2) ) +theme(aspect.ratio =1,axis.text =element_blank(),axis.ticks =element_blank(),plot.title =element_text(hjust =0.5) # Center the title horizontally )plot2 <-ggplot(data = corr_df, aes(x = x, y = y2)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", se = F) +labs(subtitle =round(cor(corr_df$x, corr_df$y2), digits =2)) +theme_minimal() +theme(aspect.ratio =1,axis.text =element_blank(),axis.ticks =element_blank(),axis.title.y =element_blank(),plot.title =element_text(hjust =0.5) # Center the title horizontally )plot3 <-ggplot(data = corr_df, aes(x = x, y = y3)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", se = F) +labs(title ="Correlation",subtitle =round(cor(corr_df$x, corr_df$y3), digits =2)) +theme_minimal() +theme(aspect.ratio =1,axis.text =element_blank(),axis.ticks =element_blank(),axis.title.y =element_blank(),plot.title =element_text(hjust =0.5) # Center the title horizontally )plot4 <-ggplot(data = corr_df, aes(x = x, y = y4)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", se = F) +labs(subtitle =round(cor(corr_df$x, corr_df$y4), digits =2)) +theme_minimal() +theme(aspect.ratio =1,axis.text =element_blank(),axis.ticks =element_blank(),axis.title.y =element_blank(),plot.title =element_text(hjust =0.5) # Center the title horizontally )plot5 <-ggplot(data = corr_df, aes(x = x, y = y5)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", se = F) +labs(subtitle =round(cor(corr_df$x, corr_df$y5), digits =1)) +theme_minimal() +theme(aspect.ratio =1,axis.text =element_blank(),axis.ticks =element_blank(),axis.title.y =element_blank(),plot.title =element_text(hjust =0.5) # Center the title horizontally )# Using patchwork to arrange plots side by side(plot1 | plot2 | plot3 | plot4 | plot5) +plot_layout(ncol =5)
We see that the more the points form a line, the closer to -1 or 1 the correlation is. We will come back to correlation when we deal with multiple linear regression later in the course.
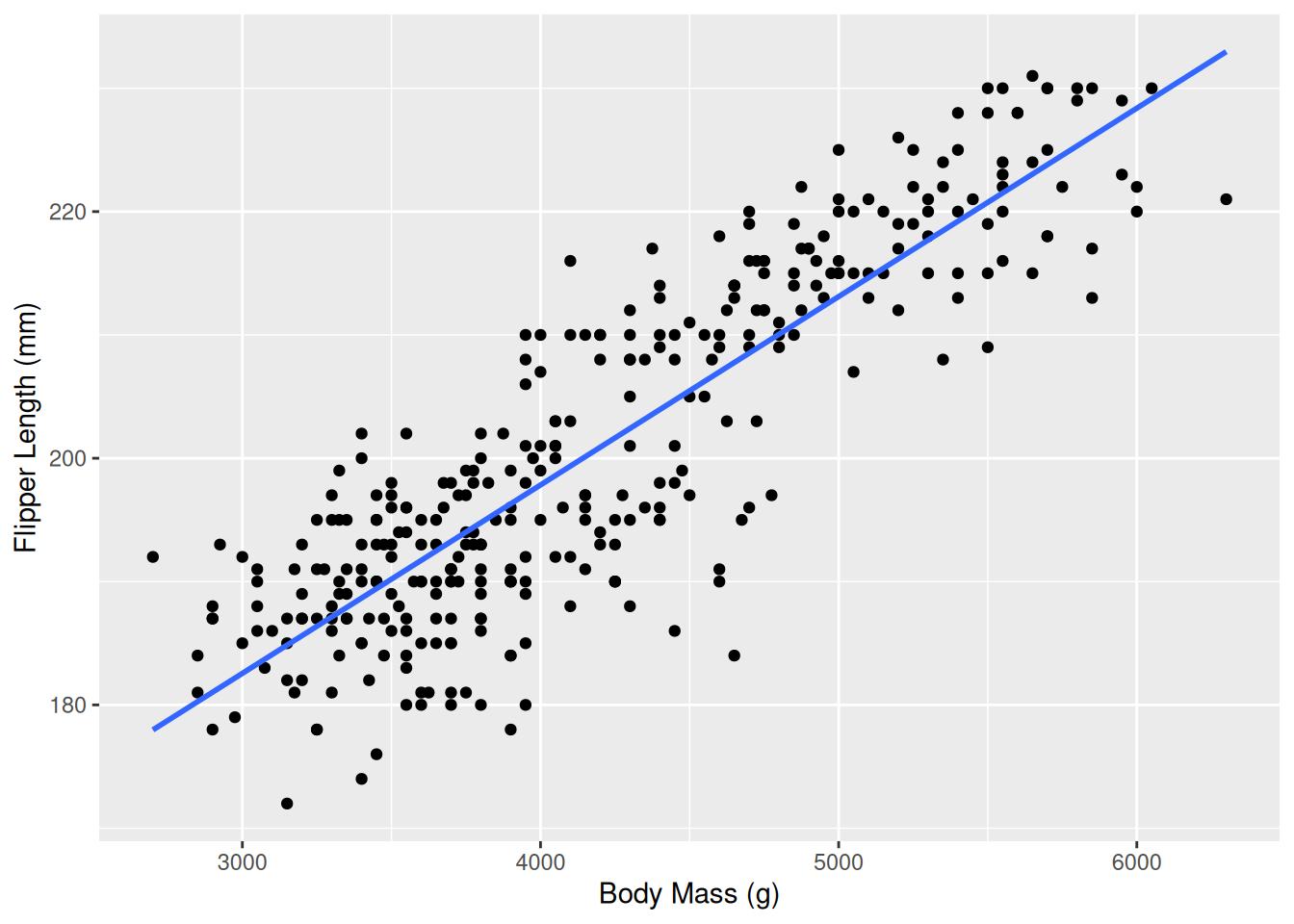
In the penguins dataset we would expect that bigger penguins have bigger flippers, that is we would expect flipper_length_mm to be positively correlated with body_mass_g. The easiest way to investigate this is through a scatter plot and a line.
Code
penguins |>ggplot(aes(x = body_mass_g, y = flipper_length_mm)) +geom_point() +geom_smooth(method ="lm", se =FALSE) +labs(x ="Body Mass (g)",y ="Flipper Length (mm)")
We see a trend: when body mass increases, flipper length increases as well, on average. We can also calculate correlation as a number using the cor function. Here we use use = "complete.obs" to make sure we don’t include missing values. This parameter fills the same function as na.rm in the mean function, but unfortunately the parameter name is different.
cor(penguins$flipper_length_mm, penguins$body_mass_g, use ="complete.obs")
[1] 0.8712018
We see that body mass and flipper length are highly positively correlated, 0.87. Finding correlated variables is an important part of data analysis as it may indicate causal effects, such as the correlation between smoking and lung cancer once did. However, correlation is no guarantee for causation, as the famous saying goes
Correlation does not imply causation.
To assert causation other assumptions or experiments are needed.
In this section you have learned about correlation between two numerical variables. In the upcoming EDA part of the course you will learn how to make visualizations to study how continuous variables vary with categorical variables, and how categorical variables vary with each other.
2.5.1 Exercises
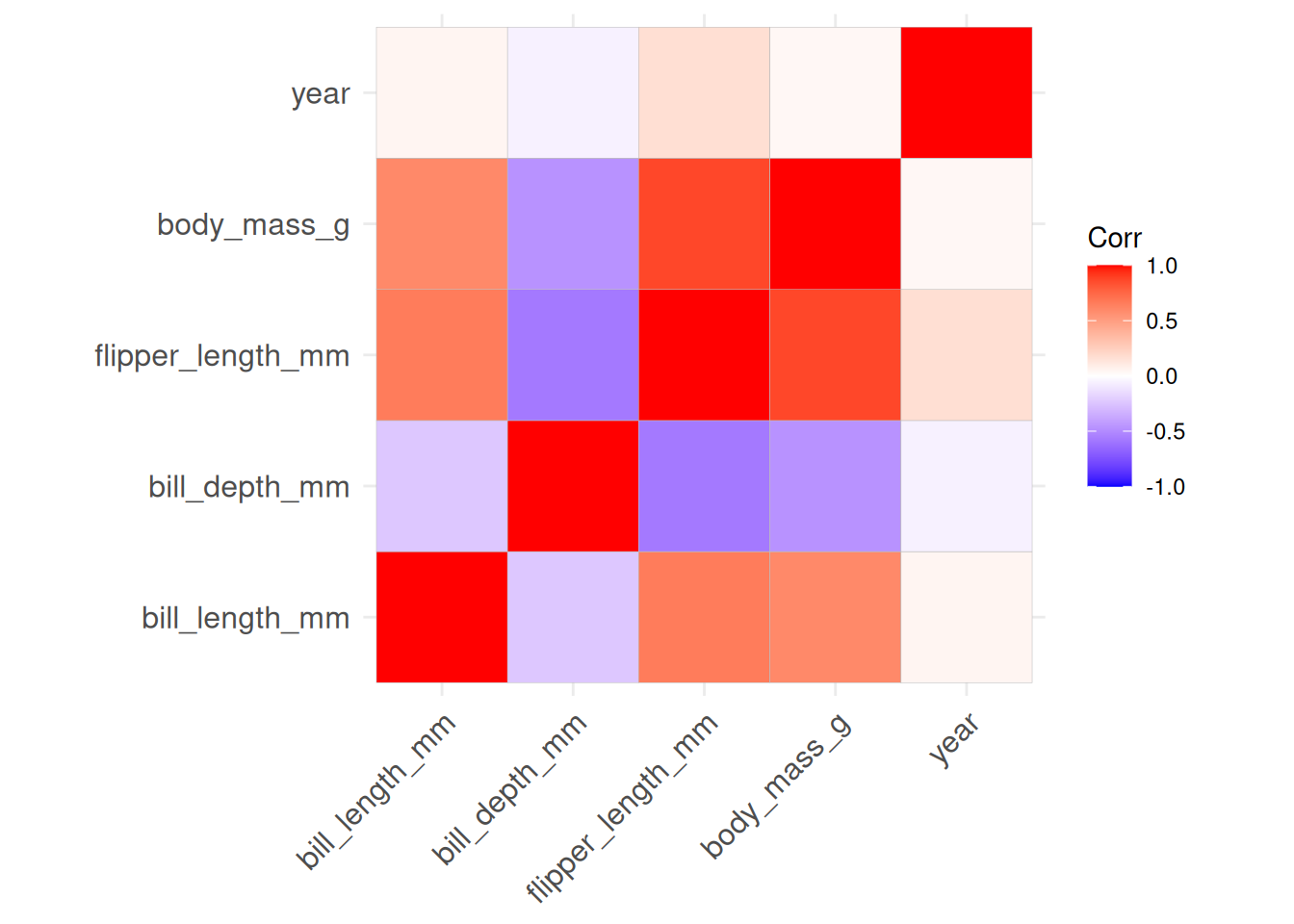
Try to understand the output of the following code that computes the correlation of all numeric variables and creates a correlation plot. Which variables are highly correlated? Does -1 mean high or low correlation? Note: Here we use the pipe operator, |>, which allows you to pass arguments to function in what is called piping. You will learn more about this in the R4DS book.
In this chapter we have covered many basic statistical concepts: from variables, their distributions, to descriptive statistics. All of these concepts are useful in data analysis and the more you work with data, the more sense they make. For now it is enough that you have an idea of these concepts and know where you can find more information about them when you need it (in this chapter or on the web!). You are now ready to dive into the core of the course: visualizing, transforming, tidying and understanding data using the course literature, R4DS. This may help you understand some of the concepts we have covered so far in a more visual way, so if it feels a bit hard right now, hang in there and you’ll see that things will become more clear.