Hypothesis testing is a systematic way of answering questions about a population using data from a random sample. It is the backbone of statistical inference and essential to have an understanding for to be able to use more powerful techniques, like linear and logistic regression. In this chapter we will be working with data presented by the Swedish national public television broadcaster, SVT, on the current election poll (19/9-2023) Väljarbarometern.
For a more technical/mathematical introduction to hypothesis testing, please consult the chapter on multiple testing (Chapter 13, 2nd edition) in An Introduction to Statistical Learning.
5.1 Sample and population
We will be using the sample in Väljarbarometern (visited 19 September 2023) collected by Kantar Public by interviewing 3072 people between August 21 and September 3, 2023. We call this a sample since it is a small part of the whole population of all citizens of Sweden.
The data comes in aggregated form, i.e. in percentages, of the 3072 people but we have recreated the original sample below. Each row is the answer of one participant in the poll and the column party shows what the person said they would vote for. Below we show the code for recreating the sample from aggregated data. You don’t need to understand the code, but if you want to recreate the sample yourself you can use the function recreate_valjarbarometern.
Code to recreate sample
library(tidyverse)recreate_valjarbarometern <-function(valjarbarometern_aggregate, n){# Calculate number of observations of each party obs_per_party <-round(n * valjarbarometern_aggregate$percentage /100)# Create a list of party observations party_observations <-mapply(rep, valjarbarometern_aggregate$party, obs_per_party)# Flatten the list into a single vector sample_data <-unlist(party_observations)# Create a data frame with the samples valjarbarometern <-tibble(party = sample_data)return(valjarbarometern)}# Number of people in surveyn =3072parties <-c("V", "S", "MP", "C", "L", "KD", "M", "SD", "Other")# Aggregated samplevaljarbarometern_aggregate <-tibble(party =factor(parties, levels = parties), # Using levels to preserve orderpercentage =c(7.6, 37.6, 4.3, 3.9, 3, 3.1, 19, 19.7, 1.7))valjarbarometern <-recreate_valjarbarometern( valjarbarometern_aggregate, n)
We can take a look at the summary of our sample
summary(valjarbarometern)
party
S :1155
SD : 605
M : 584
V : 233
MP : 132
C : 120
(Other): 239
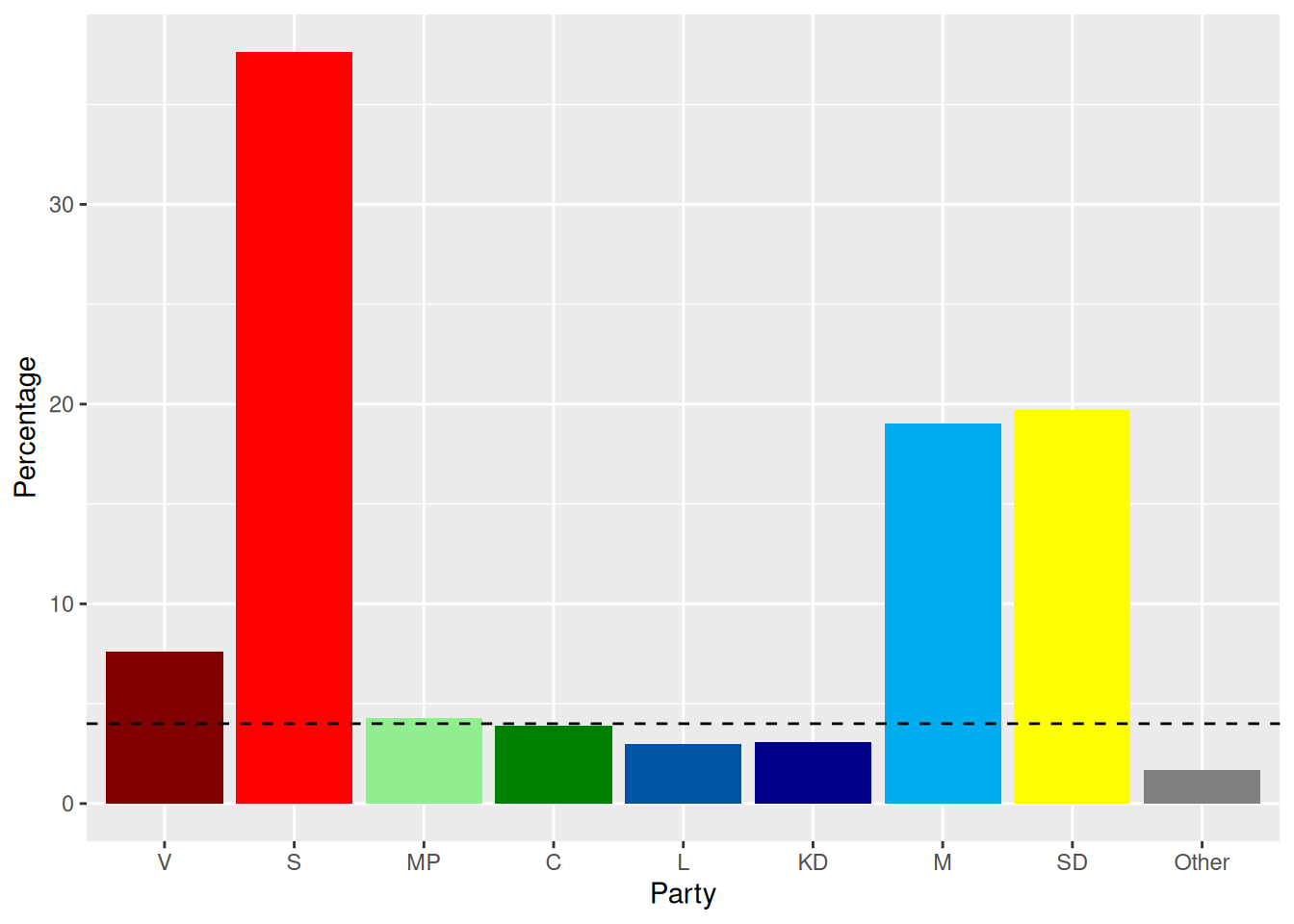
The summary tells us how many people would vote for each party if the election were today, in our sample. A more common way to look at this is using a bar chart and showing the y-axis in percentage. The dashed line indicates the limit for being included in the Swedish parliament (Sveriges riksdag), 4%.
# Define the colors in the order V, S, MP, C, L, KD, M, SD, Other. Make sure party column follows the same order!party_colors <-c("#800000", "#FF0000", "#90EE90", "#008000", "#0054A6", "#00008B", "#00AEEF", "#FFFF00", "#808080")valjarbarometern |>ggplot(aes(x = party, fill = party)) +geom_bar(aes(y =after_stat(count/sum(count) *100))) +# Calculating percentagesgeom_hline(yintercept =4,col ="black",linetype =2) +labs(x ="Party",y ="Percentage") +guides(fill ="none") +# Remove fill legendscale_fill_manual(values = party_colors) # Set colors to party colors
In our bar chart we see that several parties seems to be at risk of ending up below 4% if there was an election today: MP (Miljöpartiet) seems to be just above the 4% limit and C (Centern) just below, while L (Liberalerna) and KD (Kristdemokraterna) seem worst off. Let’s take a closer look at the percentages
n_participants <-3072# Number of participants in surveyvaljarbarometern |>summarize(percentage =round(100*n() / n, digits =1), # Calculating percentage.by = party) # Grouping by party
# A tibble: 9 × 2
party percentage
<fct> <dbl>
1 V 7.6
2 S 37.6
3 MP 4.3
4 C 3.9
5 L 3
6 KD 3.1
7 M 19
8 SD 19.7
9 Other 1.7
The summary confirms what we could tell from the bar chart, MP is just above the 4% limit with 4.3% and C is just below the limit with 3.9%. But this result comes from a sample of 3072, what does that actually tell us about how the whole population of Sweden would vote? We would like to know what the value would be if the whole population voted. To learn about this from our sample, we need to perform statistical inference, and in particular hypothesis testing.
5.1.1 Exercises
Previously we worked with the palmerpenguins dataset. What is the population in that dataset? Use ?penguins after loading the package (library(palmerpenguins)) to read more about the data. Where and when was the data collected?
5.2 Hypothesis testing (proportions)
Hypothesis testing is method that allows us to draw inferences about a population using a sample. In more simpler terms, hypothesis testing let’s us use a sample to answer questions about the population with some uncertainty. The procedures follows four steps:
1. Formulate hypotheses
Formulate the hypotheses as a null hypothesis, \(H_0\), and an alternative hypothesis, \(H_a\) (sometimes \(H_1\)). The hypotheses should reflect the question that we have: in our case, for MP, we want to know if the percentage in the population is larger than 4%. We can formulate the hypotheses for this question as
\(H_0\): The percentage of people who would vote for MP is smaller than or equal to 4%.
\(H_a\): The percentage of people who would vote for MP is larger than 4%.
\(H_0\) and \(H_a\) play different roles in hypothesis testing, \(H_0\) is our baseline and \(H_a\) represents the hypothesis we want to prove. The hypotheses should be mutually exclusive and exhaustive, that is they should cover every possible outcome. In our example the percentage must be a number between 0 and 100, which must be either smaller than or equal to 4 or larger than 4, i.e. our hypotheses cover all possibilities.
2. Calculate test statistic
Calculate a test statistic that summarizes the evidence in our data against the null hypothesis. This part is were most of mathematical and statistical theory is needed and in this course we will leave this to a test function in R. Instead we will run use a test funciton in R.
2. Use a test function in R
Run a function in R that performs a statistical hypothesis test that summarizes the evidence in our data against the null hypothesis.
3. \(p\)-value
Calculate a \(p\)-value based on the evidence, which is done by the test function. The \(p\)-value is of great importance in hypothesis testing and it is important to have a basic understanding of it. In our case, the \(p\)-value is the probability of observing 4.3% or larger (further from the null hypothesis) in a sample of 3072 people, if the null hypothesis was true. \(p\)-values can always be formulated in terms of the null hypothesis and the observed parameter, in this case the percentage voting for MP, as: “The probability of observing the observed value or more extreme, i.e. 4.3% or larger, in a sample given that the null hypothesis is true”.
4. Decision
Decide to reject or not reject the null hypothesis based on the \(p\)-value. This is a decision rule that is decided beforehand, based on a significance level, usually denoted \(\alpha\). If the \(p\)-value is smaller than the significance level, we reject the null hypothesis at significance level \(\alpha\). The most common significance level is 0.05, and we will use it throughout this course. If the \(p\)-value is smaller than 0.05 we say that the evidence in the data is statistically significant at significance level, \(\alpha\), 0.05 to reject the null hypothesis. This decision rule is dichotomous, i.e. it is either true or false. This is commonly used, but the \(p\)-value is valuable on it’s own as a \(p\)-value of 0.06 is still a very interesting result, while a \(p\)-value of 0.9 is not. A low \(p\)-value may indicate that “there may be something there”, even if it is not significant at significance level 0.05.
In practice we will not spend too much time on hypothesis testing alone in this course, but instead focus more on regression analysis where hypothesis testing is an important component. In fact, as you will see, regression analysis can be used for hypothesis testing.
5.2.1 Testing for significance
So how about MP and C? Is the percentage of people saying they would vote for MP over 4% with statistical significance? Let’s perform a hypothesis test. Note that we will be using proportions and not percentages, but it is a simple conversion, proportion = percentage / 100. Formulated in proportions our hypotheses are
\(H_0\): The proportion of people who would vote for MP is smaller than 0.04.
\(H_a\): The proportion of people who would vote for MP is larger than 0.04.
n_participants <-3072# Number of participants in surveyn_mp_voters <- valjarbarometern |># Number of participants who answered MPfilter(party =="MP") |>summarize(n =n()) |>pull(n)p_h0 <-0.04# Our null hypothesis# Conducting hypothesis test of proportions. Observe that we are testing if the proportion is *greater* than.result <-prop.test(n_mp_voters, n_participants, p_h0, alternative ="greater")result
1-sample proportions test with continuity correction
data: n_mp_voters out of n_participants, null probability p_h0
X-squared = 0.62989, df = 1, p-value = 0.2137
alternative hypothesis: true p is greater than 0.04
95 percent confidence interval:
0.03719032 1.00000000
sample estimates:
p
0.04296875
The result of our test contains a lot of information, but we only need to focus on the part that says “p-value” on the second line and read its value, rounded 0.21. Note that we should not read the p at the second to last line, as it is the proportion we observed in our sample. We compare the \(p\)-value with our significance level, 0.05 and conclude that 0.21 is larger than 0.05, and thus we can not reject our null hypothesis. This means we do not have evidence in the data that the percentage (proportion) of Sweden’s population that would vote for MP is larger than 4% (0.04), i.e. we cannot reject the null hypothesis. So the conclusion of our test is that if there was an election today MP would not be “statistically significantly” safe.
We can also access the \(p\)-value directly by accessing the p.value using the dollar operator, $, from our result.
result$p.value
[1] 0.2136985
5.2.2 Exercises
How would the hypotheses change if we were testing if the percentage that would vote on the C party is less than 4%?
Perform a hypothesis test to see if the percentage that would vote on C is statistically significant less than 4%. Reuse the code from the chapter!
Find a party that is below the 4% limit with statistical significance at significance level 0.05. Try yourself or expand the code below to see the answer. Reuse the code from the chapter!
5.3 Comments on hypothesis testing
A few important things to note in general about hypothesis testing:
We look for evidence against the null hypothesis \(H_0\), but failing to reject the null hypothesis doesn’t prove the null hypothesis is true. It only suggests that there isn’t enough statistical evidence against it.
A significantly small p-value doesn’t mean the difference between the mean under \(H_0\) and the actual population mean is large, only that it’s likely not due to chance.
The significance level should be set beforehand, not changed when the \(p\)-value is observed. Usually 0.05 is used in scientific analysis.
The significance level 0.05 is a strong indicator to reject the null hypothesis, but sometimes it may be too black and white. A \(p\)-value of 0.06 or 0.1 still indicates an interesting result, while a \(p\)-value of 0.9 does not. The \(p\)-value offers the opportunity for the reader to decide by themselves if they find the result interesting and worth further studies.
In practical applications, the outcome of hypothesis testing should be combined with domain knowledge and other information to make informed decisions or answer research questions.
When performing hypothesis testing two different errors can be committed and if you want to further study hypothesis testing and/or statistics it is important to know them.
Type I Error: When you incorrectly reject a true null hypothesis. The probability of committing this error is \(\alpha\), the significance level.
Type II Error: When you fail to reject a false null hypothesis. The probability of committing this error is denoted by \(\beta\). The power of a test, \(1 - \beta\), is the probability of rejecting a false null hypothesis.
5.4 Hypothesis test (mean)
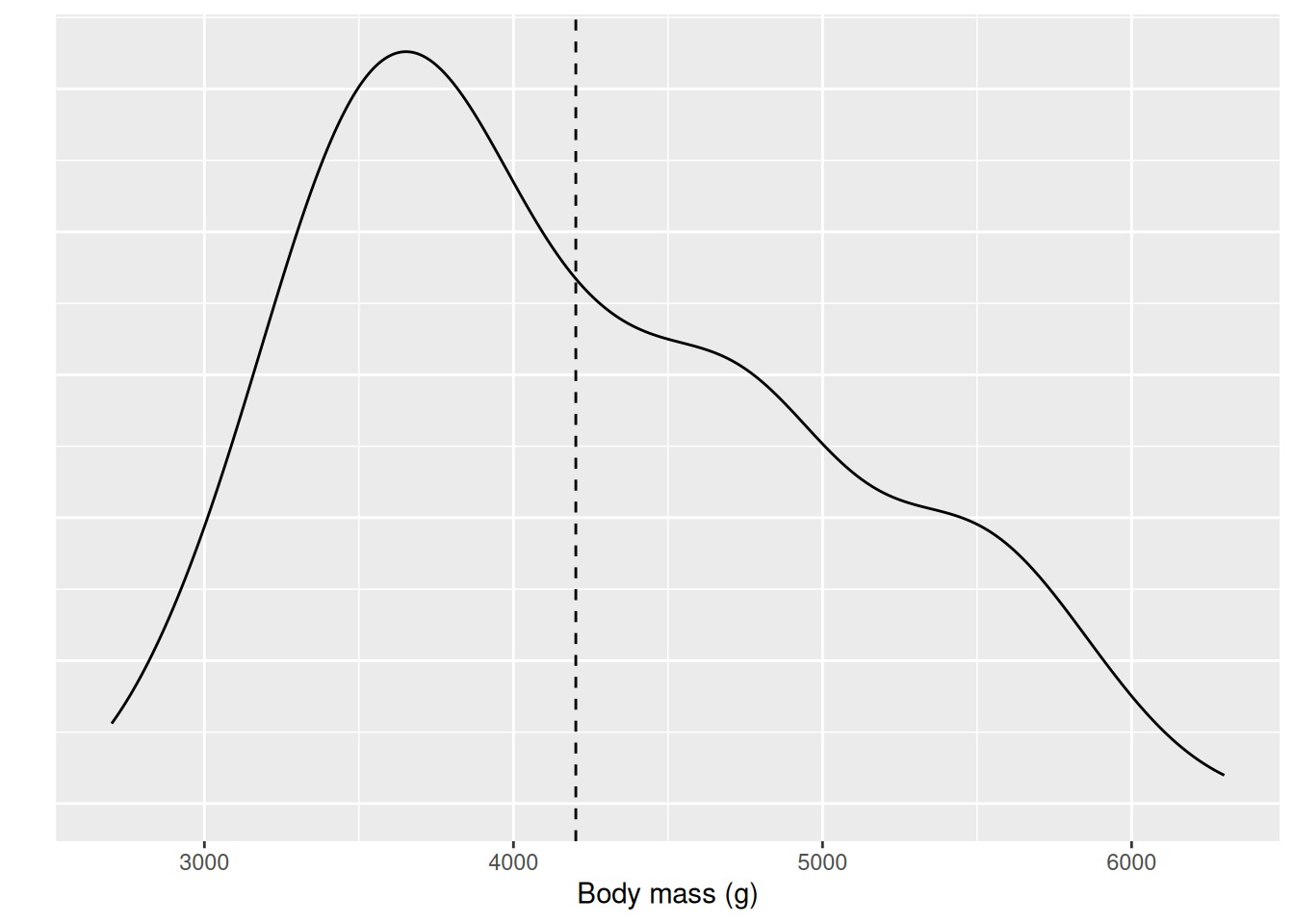
Up until now we have studied hypothesis test of proportions. A perhaps more common test is hypothesis test of the mean and difference in means. For this, we can look the penguins dataset again and specifically the variable body_mass_g, the weight of the penguins. Before we start looking at the variable we should think about our sample and population. The data was collected during the years 2007-2009 in the Palmer Archipelago, Antarctica. If we believe that the dataset is still valid for penguins in the Palmer archipelago today, we can say that our population is all penguins of the species Adelie, Chinstrap, and Gentoo in the Palmer archipelago. Now when we have identified the population we are studying, we can start by looking at the variable. We will start by visualizing the distribution over body mass and the mean body mass marked by a dashed line.
We see that there are quite a lot of observations with a smaller body mass than the mean. Can we be sure that the population mean, i.e. the mean of all penguins body weights, including those outside our sample, is above 4000 g? To test this we use a t-test. The t-test can be used we we want to ask questions about the population mean based on our sample. We formulate our hypothesis
\(H_0\): The average body mass of all penguins in the Palmer Archipelago is 4000 g.
\(H_a\): The average body mass of all penguins in the Palmer Archipelago is more than 4000 g.
We can perform this test in R using the t.test function.
t.test(penguins$body_mass_g, mu =4000, alternative ="greater")
One Sample t-test
data: penguins$body_mass_g
t = 4.6525, df = 341, p-value = 2.35e-06
alternative hypothesis: true mean is greater than 4000
95 percent confidence interval:
4130.231 Inf
sample estimates:
mean of x
4201.754
Again we are only interested in the \(p\)-value, and if it is smaller than 0.05. We see that “p-value = 2.35e-06”. Numbers with an “e” is represented using scientific notation, and it means \(2.35 \cdot 10^{-06} = 0.000000235\), which is a very, very small number. In general the number after e can be understood as the number of zeros before the first significant digit, e.g. 1.2e-02 = 0.0012. So we can conclude that at significance level 0.05 we have evidence that the mean penguin weight is more than 4000 since our \(p\)-value is smaller than 0.05.
5.5 Difference in means
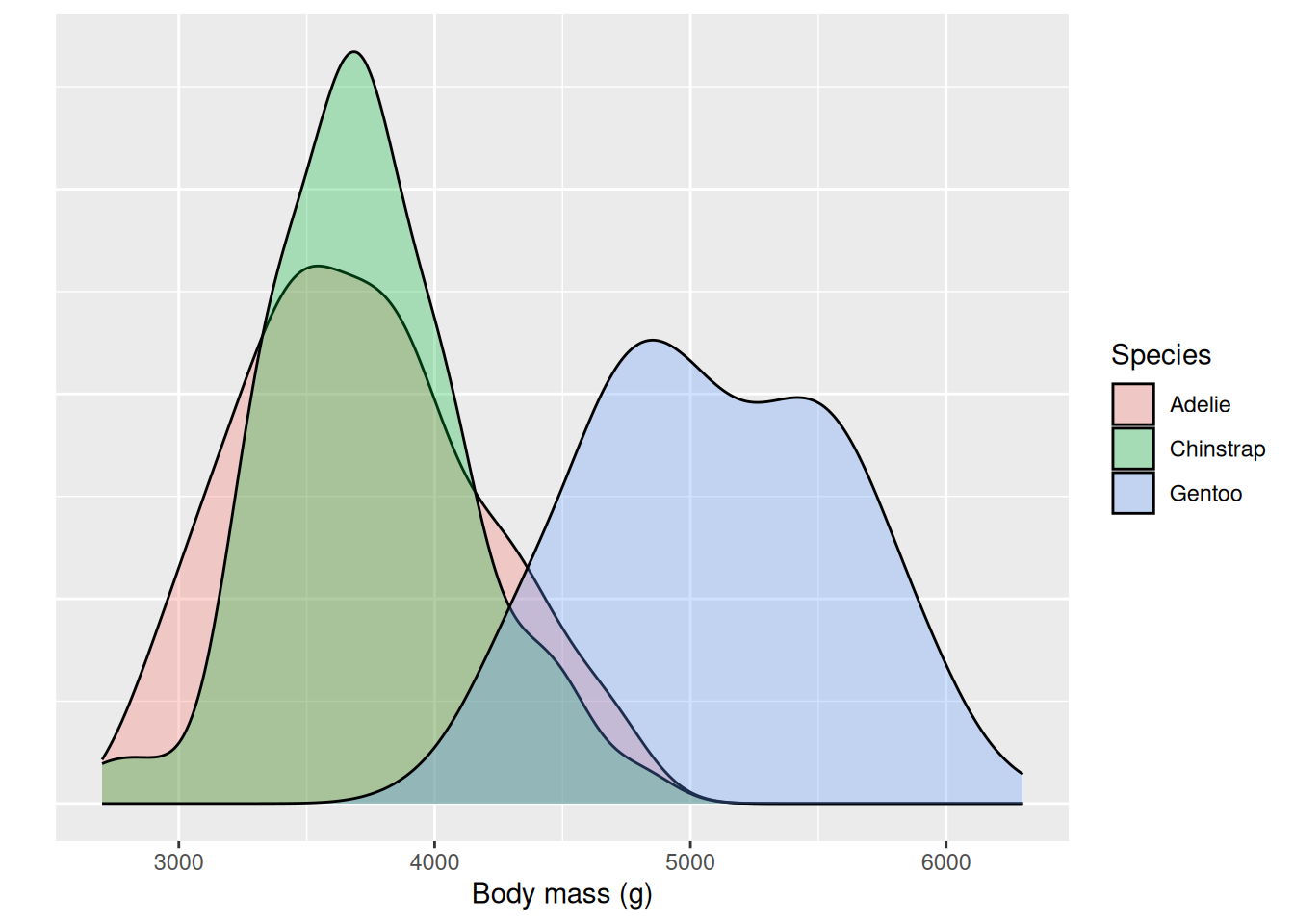
Using your skills from EDA (or memory of the Data visualization chapter in R4DS), you may have noticed that the density plot looked a bit strange: it looks like there are several densities in our sample, noticeable by the humps at around 3600, 4700, and 5500 grams. Let’s explore this further, and a good place to start is one of the categorical variables that may indicate different groups. We can visualize the density again, this time coloring the fill after the different species.
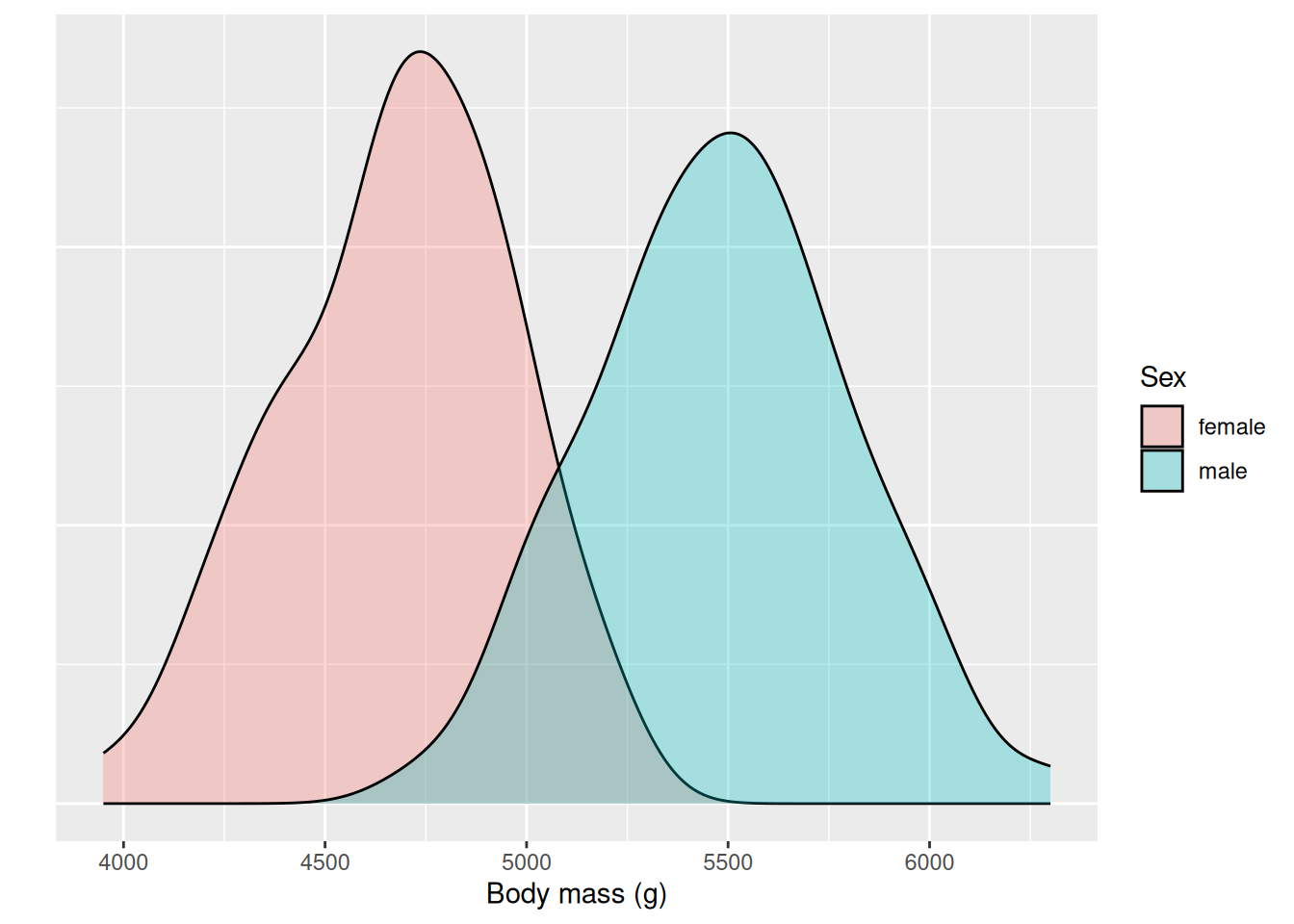
That was revealing! But still there seems to be something going on… If we look at the distribution over Gentoo penguins, we see two distinct humps again. Another categorical variable that we may suspect will affect the body mass is sex. We take a closer look at only the Gentoo penguins and color the fill based on sex instead.
# A tibble: 2 × 2
sex count
<fct> <int>
1 female 58
2 male 61
We have 58 female Gentoos and 61 males, it is not that few, but according to Wikipedia the population of Gentoos is more than 600,000 birds! Is this difference statistically significant? Again we can use a t-test to compare the mean of two groups. We formulate our hypothesis
\(H_0\): Female and male Gentoos have the same body mass on average.
\(H_a\): Female and male Gentoos do not have the same body mass on average.
We use t.test again to test for statistical significance.
female_gentoo_body_mass <- penguins |>filter(species =="Gentoo"& sex =="female") |>select(body_mass_g) |>drop_na()male_gentoo_body_mass <- penguins |>filter(species =="Gentoo"& sex =="male") |>select(body_mass_g) |>drop_na()t.test(male_gentoo_body_mass, female_gentoo_body_mass)
Welch Two Sample t-test
data: male_gentoo_body_mass and female_gentoo_body_mass
t = 14.761, df = 116.64, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
697.0763 913.1130
sample estimates:
mean of x mean of y
5484.836 4679.741
We see that the \(p\)-value is very small, \(2.2 \cdot 10^{-16}\). We conclude that we have evidence that the difference in average body weight of female and male Gentoo penguins is statistically significant at significance level 0.05.
Now we have looked at two different ways of performing hypothesis testing about different variables, either proportions or means. In the next chapter we will look at linear regression, a method that we can use to understand if there is an effect of one variable on another and to make powerful predictions.
5.5.1 Exercises
Test if the mean flipper length is more than 180 mm. Try to write down the hypotheses before you perform your test. Is the result statistically significant?
Test if the mean flipper length differs between species. Formulate the hypothesis and draw conclusions from the tests. Based on your result, is flipper length a good way to distinguish between different penguins species? You can use the code below to get started, or try yourself first.
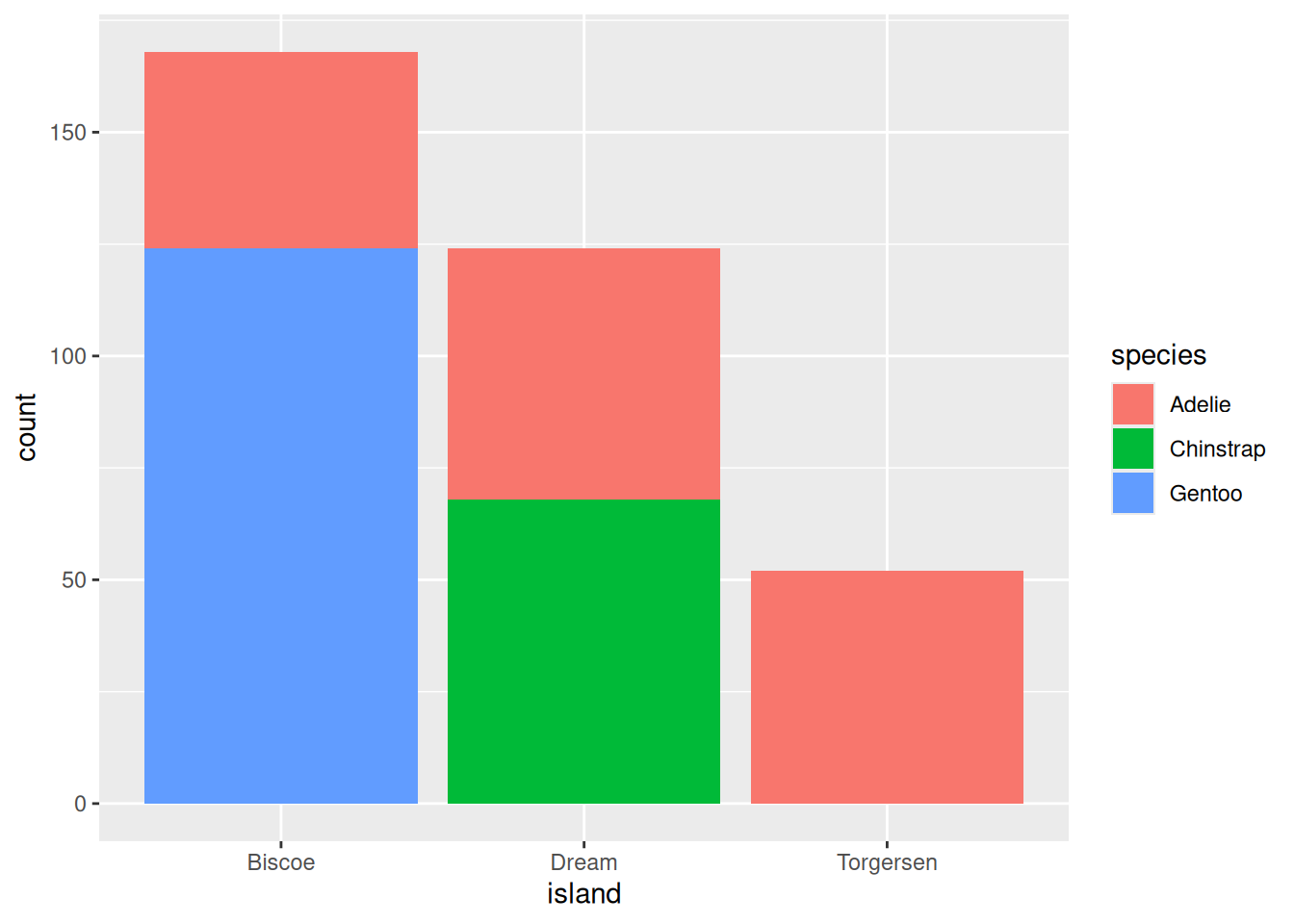
Try to figure out how to perform a proportion test to study if there are more Chinstrap penguins than Adelie on Dream island. Start by visualizing the distribution using some visualization of Island and Species. Then you will need to count the number of Chinstrap penguins on Dream island as well as the total number of penguins on Dream island. Do you see any problem with the sample we are using for this test? You can use the code below as a hint.
Code
# Visualizationpenguins |>ggplot(aes(x = island, fill = species)) +geom_bar()
Code
# Total number of penguins on Dream islandn_total <- penguins |>filter(island =="Dream") |>summarize(n =n()) |>pull()# Number of chinstrap penguins on Dream islandn_chinstrap <- penguins |>filter(species =="Chinstrap"& island =="Dream") |>summarize(n =n()) |>pull()
5.3 Comments on hypothesis testing
A few important things to note in general about hypothesis testing:
When performing hypothesis testing two different errors can be committed and if you want to further study hypothesis testing and/or statistics it is important to know them.