Just as we expanded linear regression to multiple linear rgression, we will now study multiple logistic regression. You will see that the step from knowing multiple linear regression and logistic regression to multiple logistic regression will be a very small step. When performing multiple logistic regression the hypotheses and interpretations are similar to that of multiple linear regression, they also depend on the other variables included in the model. So any conclusions that we draw based on multiple regression is always conditioned on the other variables in the model.
9.1 Blood pressure and diabetes
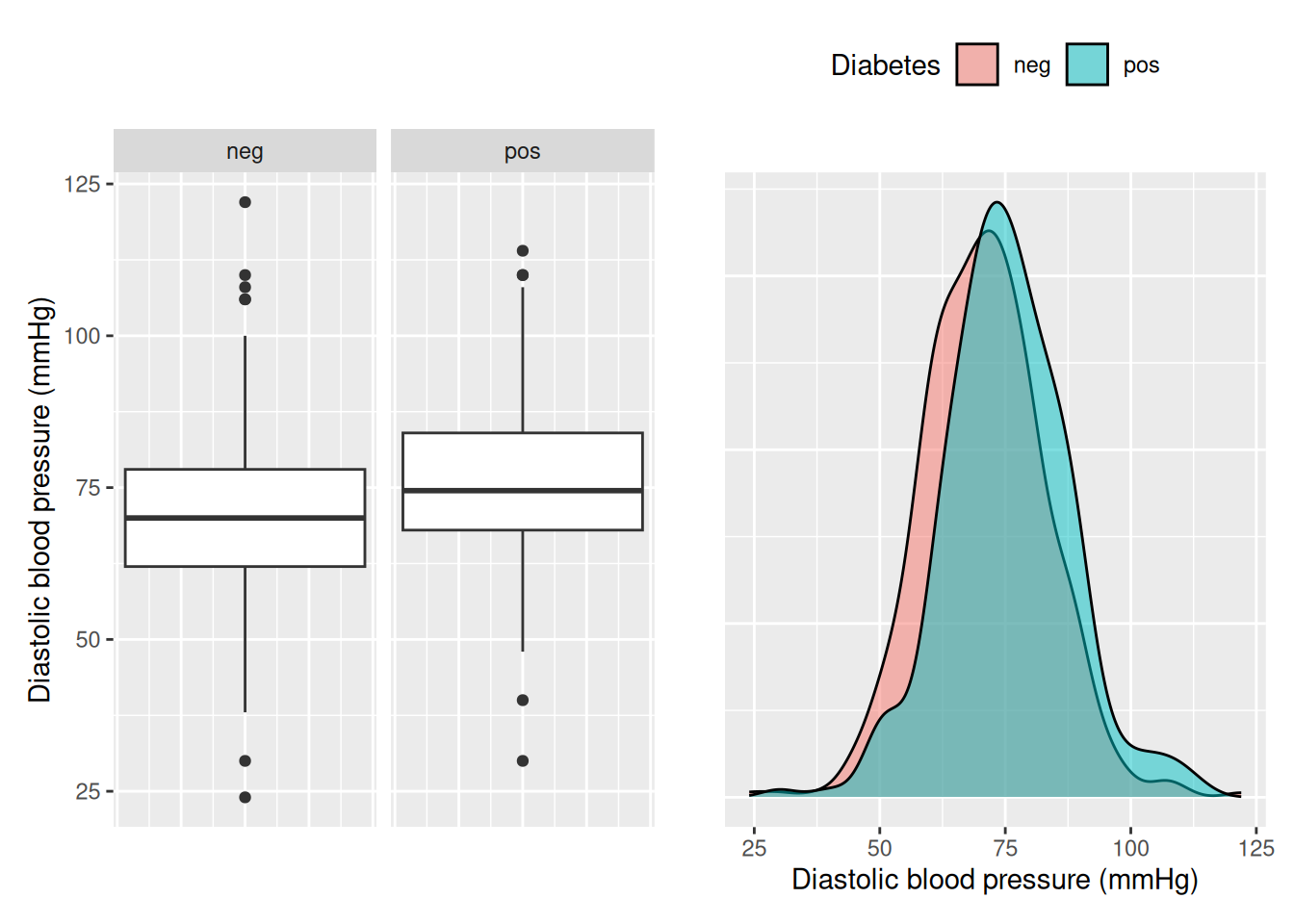
We will again use the PimaIndianDiabetes2 dataset, but this time we will start by looking at pressure, the diastolic blood pressure, as our predictor. We start by looking at the distribution over pressure.
Code
library(tidyverse)#install.packages("mlbench") # Install to get PimaIndiansDiabetes2 datasetlibrary(mlbench)data("PimaIndiansDiabetes2") # Using 2 because it is a corrected version.library(patchwork)p1 <- PimaIndiansDiabetes2 |>ggplot(aes(y = pressure)) +facet_grid(~ diabetes) +geom_boxplot() +theme(axis.text.x =element_blank(), # Remove axis textaxis.ticks.x =element_blank() # Remove axis title ) +labs(y ="Diastolic blood pressure (mmHg)")p2 <- PimaIndiansDiabetes2 |>ggplot(aes(x = pressure, fill = diabetes)) +geom_density(alpha =0.5) +theme(legend.position ="top",axis.text.y =element_blank(), # Remove axis textaxis.ticks.y =element_blank() # Remove axis title ) +labs(x ="Diastolic blood pressure (mmHg)",y ="",fill ="Diabetes" )p1 + p2
We see that there seems to be a slight relationship between blood pressure and diabetes, but the difference is not as clear as with glucose. Let’s see if the result is significant in a simple logistic regression.
model <-glm(diabetes ~ pressure, data = PimaIndiansDiabetes2, family ="binomial")model_summary <- model |>summary()model_summary$coefficients
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.83025863 0.491750376 -5.755478 8.639681e-09
pressure 0.02988395 0.006587373 4.536550 5.718197e-06
We see that there is a statistically significant, positive relationship between blood pressure and having diabetes (\(p = 5.72 \cdot 10^{-6}\)) at significance level 0.05. What if we include more variables in our model, can there be some other explanation for the relationship between blood pressure and diabetes?
9.2 Fitting multiple logistic regression models
Now we will create our multiple logistic regression model, including both pressure and mass, BMI. In the previous chapter we saw that pressure and mass have a positive linear correlation, indicating that BMI may have an effect on blood pressure, so how will it affect our logistic regression model? We state the hypotheses for the coefficient of both mass and pressure:
\(H_0\): There is no relationship between BMI and being diagnosed with diabetes, given that blood pressure is part of the model.
\(H_a\): There is a relationship between BMI level and being diagnosed with diabetes, given that blood pressure is part of the model.
and
\(H_0\): There is no relationship between blood pressure and being diagnosed with diabetes, given that BMI is part of the model.
\(H_a\): There is a relationship between blood pressure level and being diagnosed with diabetes, given that BMI is part of the model.*
Now we are ready to fit our multiple logistic regression model.
model <- PimaIndiansDiabetes2 |>glm(formula = diabetes ~ pressure + mass, family ="binomial")model |>summary()
Call:
glm(formula = diabetes ~ pressure + mass, family = "binomial",
data = PimaIndiansDiabetes2)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -4.877158 0.604581 -8.067 7.20e-16 ***
pressure 0.016488 0.006971 2.365 0.018 *
mass 0.091729 0.013218 6.940 3.93e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 938.74 on 728 degrees of freedom
Residual deviance: 864.32 on 726 degrees of freedom
(39 observations deleted due to missingness)
AIC: 870.32
Number of Fisher Scoring iterations: 4
We see that both mass and pressure ar statistically significant when included in the model and that both increase the probability of diabetes, i.e. their coefficients are both positive.
9.3 Model selection
We may also choose to include the variable triceps, which measures the triceps skin fold thickness that correlates with body fat. Let’s fit a model using triceps instead of mass.
model <- PimaIndiansDiabetes2 |>glm(formula = diabetes ~ pressure + triceps, family ="binomial")model |>summary()
Call:
glm(formula = diabetes ~ pressure + triceps, family = "binomial",
data = PimaIndiansDiabetes2)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -4.003582 0.628387 -6.371 1.88e-10 ***
pressure 0.024955 0.008167 3.055 0.00225 **
triceps 0.050017 0.009960 5.022 5.12e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 685.23 on 538 degrees of freedom
Residual deviance: 638.43 on 536 degrees of freedom
(229 observations deleted due to missingness)
AIC: 644.43
Number of Fisher Scoring iterations: 4
Again we see that both variables are significant at significance level 0.05, but which model is the best? In linear regression we could use the adjusted R\(^2\), but it doesn’t apply to logistic regression. Instead we are going to use the Akaike Information Criterion (AIC). AIC scales with the number of observations, so, in contrast to R\(^2\), the AIC of a model on its own is not useful. Here we will use it to compare models and argue for one model over another. Later in this chapter we will introduce accuracy as a way of measuring the performance of a logistic regression model.
To be able to tell which logistic regression model is better, we can look at the summary output and second to last line: “AIC”. AIC estimates the prediction error of the model, where a lower AIC is better. We can compare the two models that we fitted before, either by looking at the summary output (see above), or using the $ operator and aic.
We see that the model including triceps and pressure has a lower AIC and is thus a preferable model.
AIC is more similar to R\(^2\) adjusted than R\(^2\) in that it also penalizes more complex models. There is a “cost” to adding a new variable to the model and if it doesn’t increase how well the model describes the data, the AIC will increase.
9.3.1 Exercises
Which of the two models diabetes ~ triceps and diabetes ~ pressure has the lowest AIC?
Fit a logistic regression model for diabetes ~ pressure + mass + triceps. Is the AIC value lower? What about the VIF values? Remember you can calculate the VIF value using the vif function from the car library.
9.3.2 Model selection strategies
When creating a multiple logistic regression model you may use any model selection strategy discussed in Section 7.5. Whenever possible it is good to use domain or expert knowledge (D/E knowledge), and otherwise it is good to try either backward, forwards, or mixed selection and motivate the final model either based on AIC and significance or D/E knowledge.
Adding more variables tend to reduce the AIC, as long as they improve the model more than the penalty of adding a variable. We saw this when comparing the models of with triceps, mass, and pressure alone vs the models including two or more variables. We can add all the variables in the dataset using the dot, ., and build a model using backward selection.
model <- PimaIndiansDiabetes2 |>glm(formula = diabetes ~ ., family ="binomial")model |>summary()
Call:
glm(formula = diabetes ~ ., family = "binomial", data = PimaIndiansDiabetes2)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.004e+01 1.218e+00 -8.246 < 2e-16 ***
pregnant 8.216e-02 5.543e-02 1.482 0.13825
glucose 3.827e-02 5.768e-03 6.635 3.24e-11 ***
pressure -1.420e-03 1.183e-02 -0.120 0.90446
triceps 1.122e-02 1.708e-02 0.657 0.51128
insulin -8.253e-04 1.306e-03 -0.632 0.52757
mass 7.054e-02 2.734e-02 2.580 0.00989 **
pedigree 1.141e+00 4.274e-01 2.669 0.00760 **
age 3.395e-02 1.838e-02 1.847 0.06474 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 498.10 on 391 degrees of freedom
Residual deviance: 344.02 on 383 degrees of freedom
(376 observations deleted due to missingness)
AIC: 362.02
Number of Fisher Scoring iterations: 5
The AIC value reduced to 362.02, which is much lower than the previous models. But we have several variables that are not significantly related to diabetes, with pressure now having a \(p\)-value larger than 0.9. We remove pressure from our model using the formula diabetes ~ . - pressure.
model <- PimaIndiansDiabetes2 |>glm(formula = diabetes ~ . - pressure, family ="binomial")model_summary <- model |>summary()model_summary$aic
[1] 360.0356
We see that the AIC reduced even more by removing pressure, illustrating the penalty in AIC for including variables that doesn’t improve the models ability to explain the data.
Note: using . in the formula in glm removes all observations with missing values in the data before fitting the model. When comparing models . is good, but when fitting the final model intended for inference or prediction it is recommended to either handle missing values explicitly or stating included predictors explicitly in the formula using +. See Section 7.4.2 for more details.
9.3.3 Exercises
Continue the backward selection process based on the model above. What is the lowest AIC you can achieve? Note that this exercise is contained in Assignment 2.
9.4 Prediction
Just as with simple logistic regression we can use our model to predict. We need to provide a data.frame (or tibble) with values for the predictors in the fitted model. We can use the model we fitted before, diabetes ~ pressure + triceps, to predict the probability of the onset of diabetes within five years for a woman with diastolic blood pressure 75 mm Hg and triceps skin fold thickness 30 mm. To get the output as a probability we also need to provide the parameter type = "response".
# Triceps modelmodel_triceps <- PimaIndiansDiabetes2 |>glm(formula = diabetes ~ pressure + triceps, family ="binomial")model_triceps |>predict(data.frame(pressure =75, triceps =30), type ="response")
1
0.3471786
The probability of the onset of diabetes within five years for a women of the Pima Indian population with diastolic blood pressure 75 mm Hg and 30 mm triceps skin fold thickness is \(\sim 0.35\) according to our model. If we want our prediction to fall into the classes “diabetes positive” or “diabetes negative”, we may use 0.5 as a cutoff. Then any predicted probability of more than 0.5 will be considered as positive and below 0.5 as negative. We can use the ifelse function to achieve this.
In this case, the prediction is negative, since the probability was below 0.5.
9.5 Accuracy
In addition to AIC, we can evaluate the performance of our model using prediction by measuring the accuracy of our model. Accuracy is the ratio of correct predictions over the total number of predictions, \(\text{Accuracy} = \#\text{Correct predictions} / \#\text{Total predictions}\). We can calculate the accuracy of the model above on our dataset by predicting the probability of diabetes for all (complete) observations and then comparing to the observed values of diabetes. To compare with diabetes, we set the predicted outcome to positive, pos, if the predicted probability is larger than 0.5.
model <- PimaIndiansDiabetes2 |>glm(formula = diabetes ~ . - pressure, family ="binomial")# Calculating the accuracyPimaIndiansDiabetes2 |># Calculated the predicted probabilities for all observationsmutate(predicted_prob = model |>predict(PimaIndiansDiabetes2, type ="response")) |># Predicting the outcomemutate(predicted_outcome =ifelse(predicted_prob >0.5, "pos", "neg")) |># Dropping predictions with missing valuesfilter(!is.na(predicted_outcome)) |># Summarizing Accuracy = # Correct predictions / # Total predictionssummarize(accuracy =mean(predicted_outcome == diabetes))
accuracy
1 0.7831633
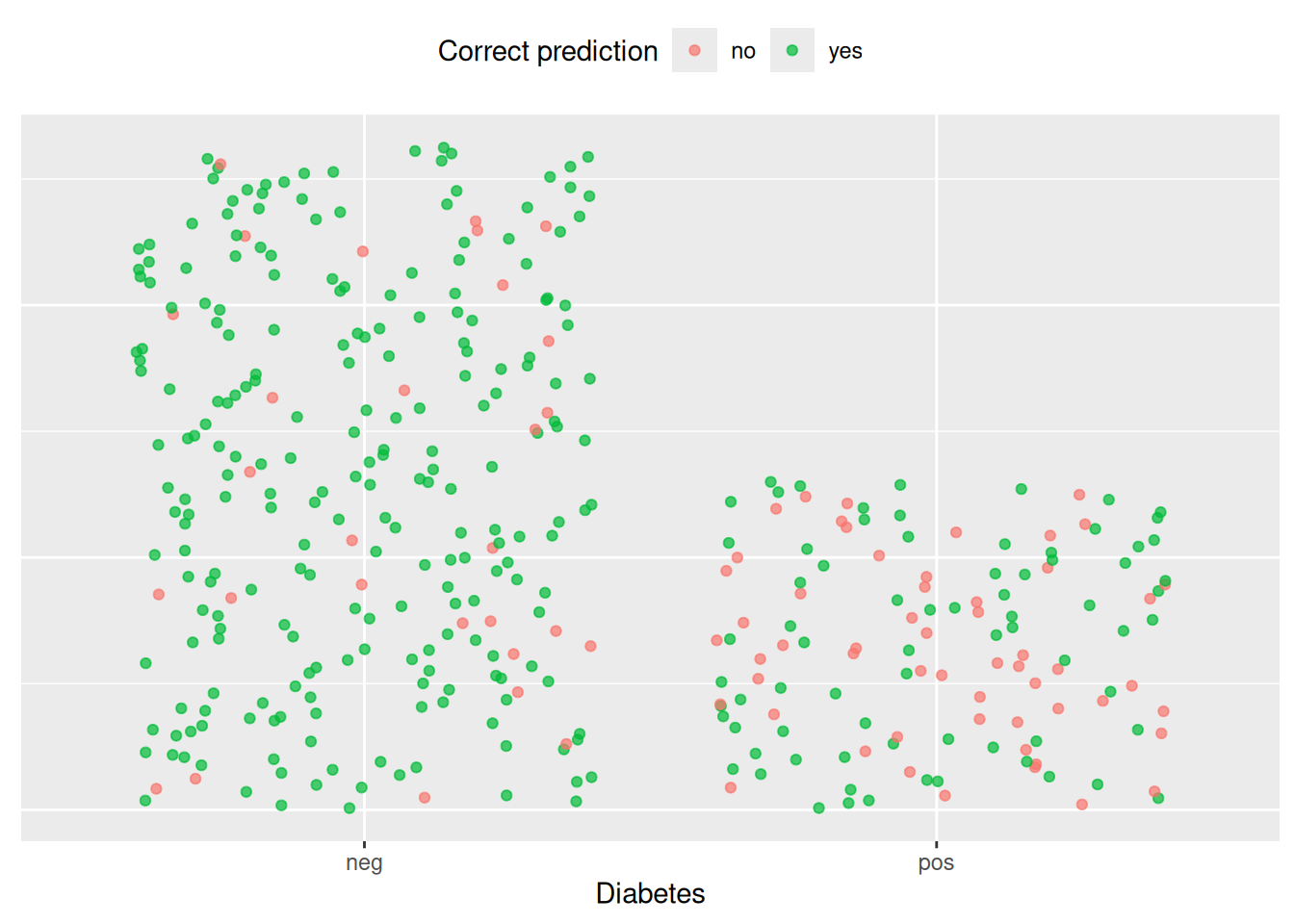
We see that our model has an accuracy of \(\sim 0.78\), predicting the observed outcome in 78% of the cases in the dataset. Accuracy may be intuitive to measure the predictive performance of the model, but it may be misleading. If we look at how well the model predicts within each class, i.e. diabetic positive and negative, we see that the model is better att predicting negative outcomes than positive. Here we visualize each observation in two columns, one for diabetes negative and one for positive, and then color on wether the prediction is correct or not.
Code
library(scales)hex <-hue_pal()(3)set.seed(42) # For reproducibilityPimaIndiansDiabetes2 |># Calculated the predicted probabilities for all observationsmutate(predicted_prob = model |>predict(PimaIndiansDiabetes2, type ="response")) |># Dropping predictions with missing valuesdrop_na() |># Predicting the outcomemutate(predicted_outcome =factor(ifelse(predicted_prob >0.5, "pos", "neg"))) |>mutate(correct_prediction =factor(ifelse(predicted_outcome == diabetes, "yes", "no"))) |>mutate(index =row_number(), .by = diabetes) |>arrange(index) |>ggplot(aes(x = diabetes, y = index, col = correct_prediction)) +geom_jitter(alpha =0.7) +labs(x ="Diabetes",col ="Correct prediction") +scale_color_manual(values =c(hex[1], hex[2])) +theme(legend.position ="top",axis.title.y =element_blank(),axis.text.y =element_blank(),axis.ticks.y =element_blank(), )
We see that our model is better at predicting negative outcomes than positive outcomes. We may consider another cut-off to be more strict or lenient in how many cases we classify as diabetic. We may want to lower the cut-off to screen more women for diabetes rather than fewer, if that is what the model is used for. In general it is good to also report other metrics, such as precision, recall, and F-score, to give a better idea of the performance of the model. In this course we will not be considering either of these, and simply use 0.5.
Usually when calculating accuracy the data is split in a training and test set, where the model is trained on the training set and then the accuracy is tested on the test set. This way the models overfitting to the sample is evaluated as well.
9.5.1 Exercises
Calculate the accuracy of the model including all potential predictors, i.e. include pressure. Is the accuracy better?
Calculate the accuracy of the best model you found before (i.e. lowest AIC). How does it compare to the model including all variables?
Run the code below to test the accuracy of the models with and without pressure using a training and test set. Try varying the seed. Do you think we should include pressure or not? Note: You don’t have to use a training and test set in the assignments in this course.
Code
# Set seed for reproducibilityset.seed(42) # Create an index to keep track of subjectspima <- PimaIndiansDiabetes2 |>drop_na() |># Using only complete observationsmutate(index =1:n())# Create training and testing settraining_set <- pima |>sample_frac(0.8) # Use 80% of the data in training settest_set <- pima |>anti_join(training_set, by ="index")# Train model on training setmodel <- training_set |>glm(formula = diabetes ~ ., family ="binomial")# Evaluate model by accuracy on test setpredictions <- model |>predict(test_set, type ="response")test_set |>mutate(prediction =ifelse(predictions >0.5, "pos", "neg")) |>summarize(accuracy =mean(prediction == diabetes))
Consider a very unbalanced dataset of 100 observations with a binary outcome, “yes” or “no”. In the dataset, 90% of the observations have outcome “yes”. What accuracy would a model that always predicts “yes” get? Hint: This exercise is better done with pen and paper, using the formula for accuracy.
9.6 Summary
This concludes the part on logistic regression. We have seen that logistic regression is suitable when our outcome is a binary categorical variable, how to compare logistic regression models, and how to compute accuracy.
When faced with a modelling problem, it is important to understand if it is a regression problem or classification problem and select an appropriate method, e.g. linear or logistic regression, where regression problems deal with continuous outcomes and classification problems categorical outcomes.
After these chapters you should be able to identify the type of problem and apply the appropriate method.