In the last chapter we got a taste of multiple linear regression when we included species to fit the relationship between body_mass_g and bill_depth_mm. In this chapter we will continue fitting regression models with multiple predictors, capable of explaining more of the variation in the response (dependent variable). Multiple linear regression is a powerful tool, but it requires some care in order to create a model that is both good at prediction and interpretable, i.e. a model that we can easily understand with coefficients that make sense and that the model doesn’t get too big to understand. Sometimes we have to/should sacrifice explanatory power in benefit of a simpler model.
To study multiple linear regression we will use an anonymized dataset on the birth weight of children, given to us from the medical faculty at Umeå University. Our goal is to analyze what affects the birth weight of children given the variables in the dataset, which is available on Canvas if you want to do the exercises or reproduce any analysis made in this chapter.
7.1 Birth weight dataset
The dataset was collected at a hospital in Sweden and consists of observations of 230 children. We can take a glimpse at the dataset to see what variables it contains. First we load the dataset using read_csv.
library(tidyverse)birth <-read_csv("datasets/birth.csv") # Remember to set the correct pathglimpse(birth)
Our response variable is birth weight in grams and the predictors are: pregnancy duration in weeks, the sex of the child, and age, length, weight, and BMI of the mother. We can see that sex is coded as a numerical variable (double) and we should start by recoding it as a factor. In the dataset males are encoded as 1 and females as 2.
# Recoding sex as factorbirth <- birth |>mutate(sex =as.factor(ifelse(sex ==1, "Male", "Female")))
Lets explore our data using EDA. Since we are interested in linear regression, we can start by plotting the response against the predictors. We use scatter plots for the numerical variables and a box plot for sex.
Code
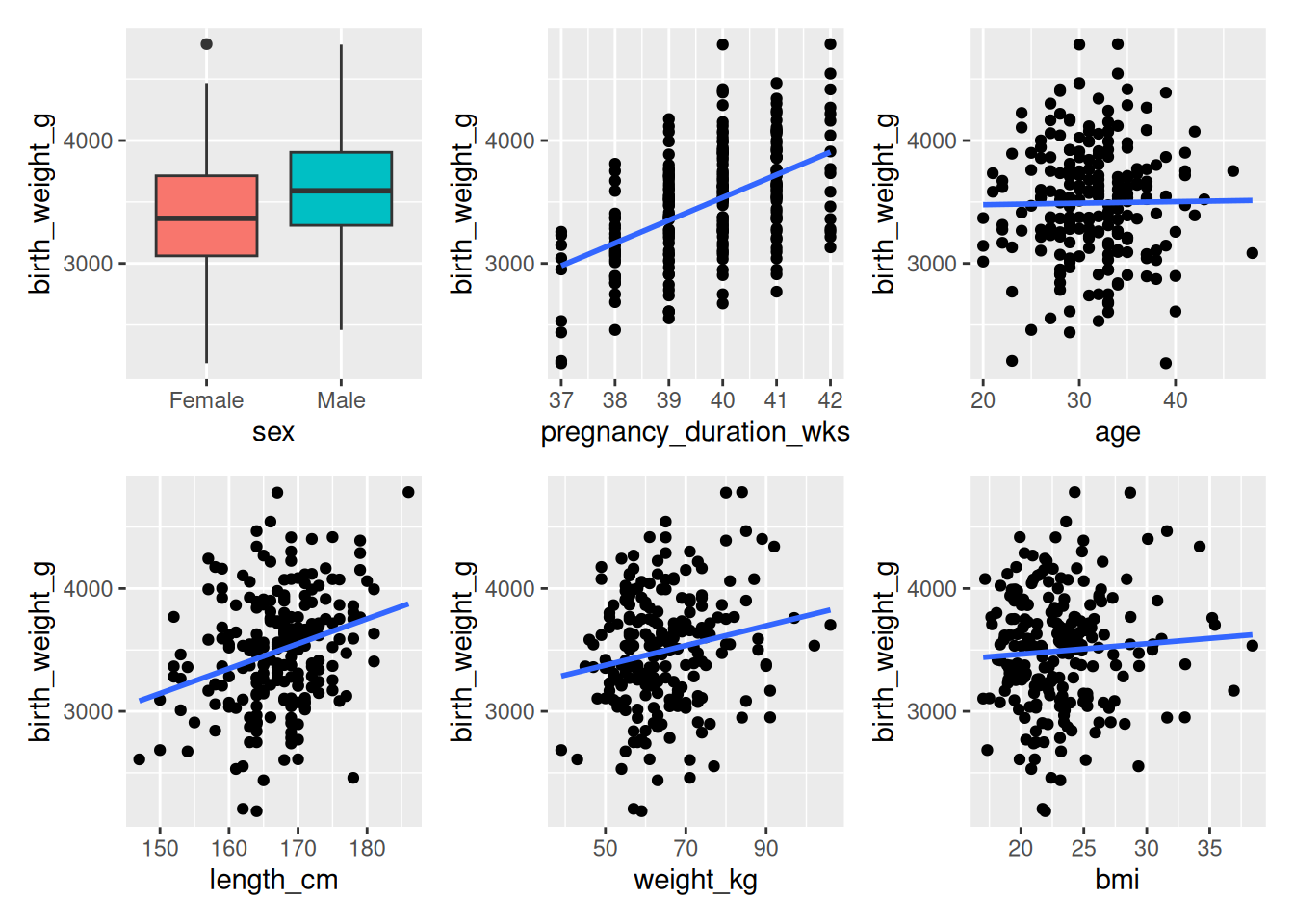
library(patchwork)p0 <- birth |>ggplot(aes(x = sex, y = birth_weight_g, fill = sex)) +geom_boxplot() +guides(fill =FALSE)p1 <- birth |>ggplot(aes(x = pregnancy_duration_wks, y = birth_weight_g)) +geom_point() +geom_smooth(method ="lm", se =FALSE) p2 <- birth |>ggplot(aes(x = age, y = birth_weight_g)) +geom_point() +geom_smooth(method ="lm", se =FALSE)p3 <- birth |>ggplot(aes(x = length_cm, y = birth_weight_g)) +geom_point() +geom_smooth(method ="lm", se =FALSE)p4 <- birth |>ggplot(aes(x = weight_kg, y = birth_weight_g)) +geom_point() +geom_smooth(method ="lm", se =FALSE)p5 <- birth |>ggplot(aes(x = bmi, y = birth_weight_g)) +geom_point() +geom_smooth(method ="lm", se =FALSE)(p0 + p1 + p2) / (p3 + p4 + p5)
It seems like there is a linear relationship between birth weight and pregnancy duration and mother length, weight, and possibly BMI. The distribution of birth weight over the two sexes also seems to be different, indicating that the mean birth weight may differ between females and males. Another way of quickly assessing the strength of the linear relationships between variables is a correlation plot. First we compute the pairwise correlations of the numeric variables using cor.
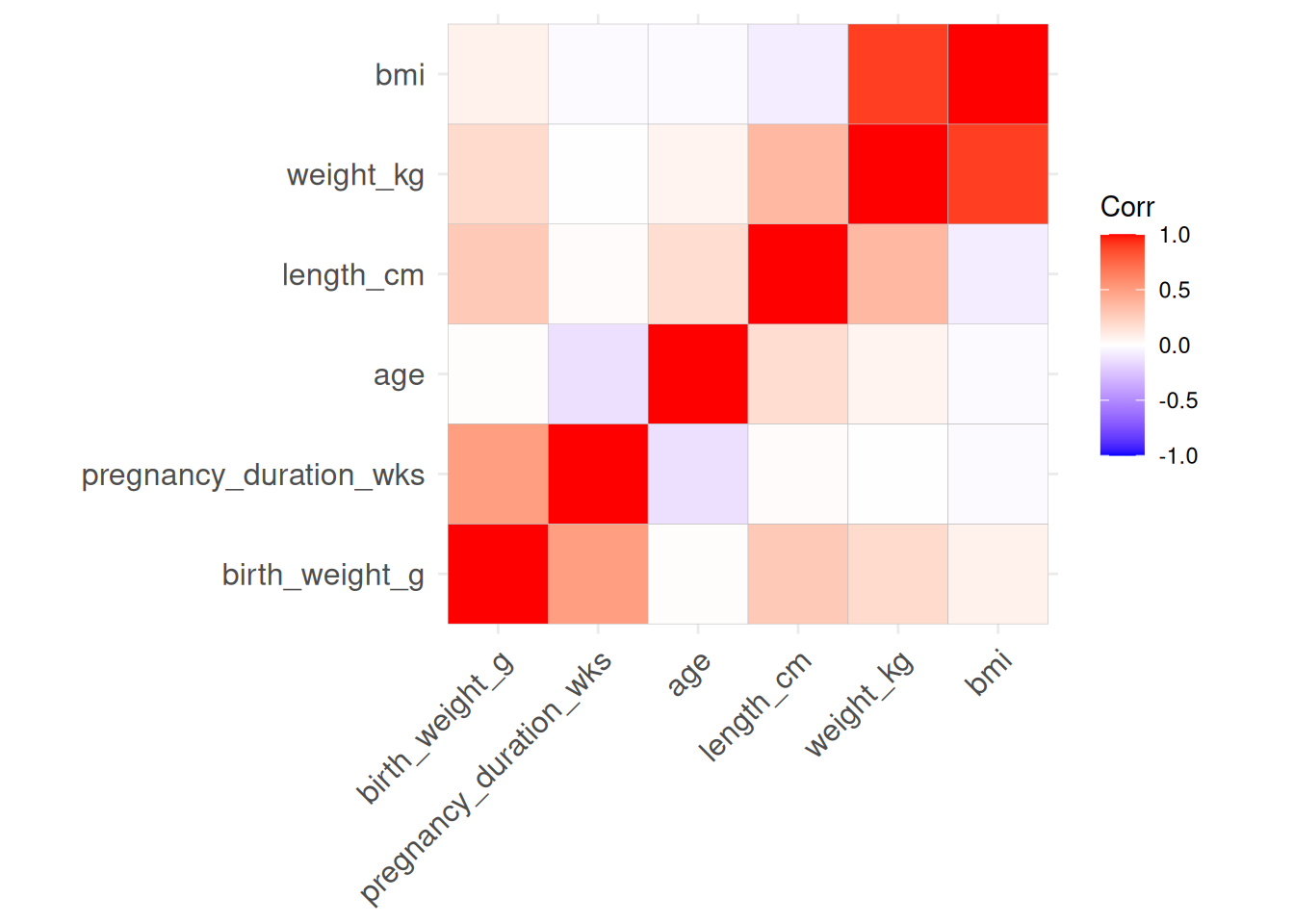
library(ggcorrplot)# You can also use #library(corrplot)birth |>select(where(is.numeric)) |>cor() |>ggcorrplot()
Looking at the row or column for birth_weight_g lets us quickly see that all other variables are positively correlated with birth_weight_g, as red indicates positive correlation (see the legend “Corr”), confirming what we saw in our the scatter plots before. We will revisit correlation from a the perspective of linear regression in a moment, but first we will ask ourselves if these results are statistically significant, i.e. if the result holds in the population or is just the result of chance, by performing simple linear regression.
7.1.1 Exercises
What is the population that generated this sample? Would you like to know more about the sample to better specify the population? Are there more variables that could be interesting for predicting birth weight?
Perform simple linear regression of birth_weight_g ~ age to see if there is a significant linear relationship. State the null and alternative hypotheses and analyze the result using significance level 0.05.
Perform simple linear regression of birth_weight_g ~ length_cm, birth_weight_g ~ weight_kg, and birth_weight_g ~ bmi to see if there is a significant linear relationship between the variables.
7.2 Comparing models
Before we can start performing multiple linear regression we must learn how to compare models and what constitutes a good model.
In the previous exercises we fitted several linear models to predict the birth weight of the child. Two of them were significant, the models using length_cm and weight_kg as predictors, while age and bmi did not show a significant linear relationship with birth_weight_g. A natural question to ask is which of the two models birth_weight_g ~ length_cm and birth_weight_g ~ weight_kg is the best, but how do we determine if a model is better than another?
7.2.1 Correlation revisited
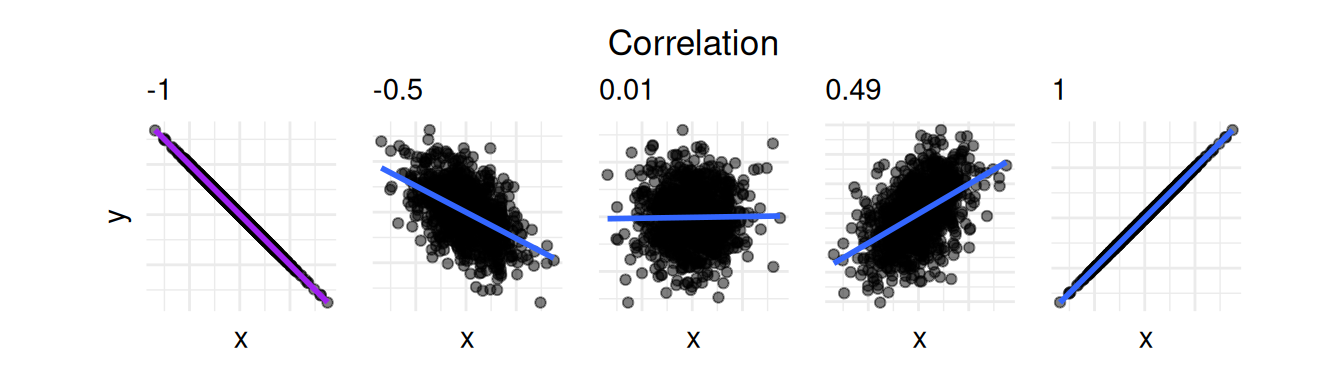
In Section 2.5 we briefly touched upon correlation and looked at this figure, where strong correlation is indicated by values close to -1 and 1 and values close to 0 indicate weak or no correlation.
Code
library(patchwork)set.seed(42) # Setting a seed to get the same output every time.# Generating x and y variables based on different correlation scenariosN <-1000x <-rnorm(N)y1 <--x +rnorm(N, sd =0.01) # Correlation ~ -1y2 <--0.5* x +rnorm(N, sd =sqrt(0.75)) # Correlation ~ -0.5y3 <-rnorm(N) # Correlation ~ 0y4 <-0.5* x +rnorm(N, sd =sqrt(0.75)) # Correlation ~ 0.5y5 <- x +rnorm(N, sd =0.01) # Correlation ~ 1# Creating a data framecorr_df <-data.frame(x, y1, y2, y3, y4, y5)# Creating individual plots with titles and modified themesplot1 <-ggplot(data = corr_df, aes(x = x, y = y1)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", se = F, col ="purple") +theme_minimal() +labs(y ="y", subtitle =round(cor(corr_df$x, corr_df$y1), digits =2) ) +theme(aspect.ratio =1,axis.text =element_blank(),axis.ticks =element_blank(),plot.title =element_text(hjust =0.5) # Center the title horizontally )plot2 <-ggplot(data = corr_df, aes(x = x, y = y2)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", se = F) +labs(subtitle =round(cor(corr_df$x, corr_df$y2), digits =2)) +theme_minimal() +theme(aspect.ratio =1,axis.text =element_blank(),axis.ticks =element_blank(),axis.title.y =element_blank(),plot.title =element_text(hjust =0.5) # Center the title horizontally )plot3 <-ggplot(data = corr_df, aes(x = x, y = y3)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", se = F) +labs(title ="Correlation",subtitle =round(cor(corr_df$x, corr_df$y3), digits =2)) +theme_minimal() +theme(aspect.ratio =1,axis.text =element_blank(),axis.ticks =element_blank(),axis.title.y =element_blank(),plot.title =element_text(hjust =0.5) # Center the title horizontally )plot4 <-ggplot(data = corr_df, aes(x = x, y = y4)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", se = F) +labs(subtitle =round(cor(corr_df$x, corr_df$y4), digits =2)) +theme_minimal() +theme(aspect.ratio =1,axis.text =element_blank(),axis.ticks =element_blank(),axis.title.y =element_blank(),plot.title =element_text(hjust =0.5) # Center the title horizontally )plot5 <-ggplot(data = corr_df, aes(x = x, y = y5)) +geom_point(alpha =0.5) +geom_smooth(method ="lm", se = F) +labs(subtitle =round(cor(corr_df$x, corr_df$y5), digits =1)) +theme_minimal() +theme(aspect.ratio =1,axis.text =element_blank(),axis.ticks =element_blank(),axis.title.y =element_blank(),plot.title =element_text(hjust =0.5) # Center the title horizontally )# Using patchwork to arrange plots side by side(plot1 | plot2 | plot3 | plot4 | plot5) +plot_layout(ncol =5)
Now that we know linear regression we are better equipped to understand what correlation really means: two variables are highly correlated if they linearly describe each other well. They correlate perfectly if all the points fall in a line, as for correlation -1 and 1. In this case, estimating a linear regression model will yield a very small \(p\)-value, while fitting a regression model where the correlation is closer to zero is more likely to yield an non-significant linear relationship. It is important to remember that the correlation does not tell us anything about the strength of the relationship, i.e. the size of the coefficient, but only how well the points fall on the regression line and if the coefficient is positive or negative.
Correlation sounds like a good candidate to assert which one of our two models are the best at describing our outcome, and indeed correlation can be used for this in simple linear regression, but for multiple linear regression there is no one correlation for the whole model. Instead, the coefficient of determination, or R\(^2\) pronounced “R-squared” is used. In the case of simple linear regression it has a simple relation ship with correlation, as R\(^2\) = Correlation\(^2\). In both simple and multiple linear regression the interpretation of R\(^2\) is very intuitive, which makes it a very good measure of how well a model describes the outcome.
7.2.2 Coefficient of determination, R\(^2\)
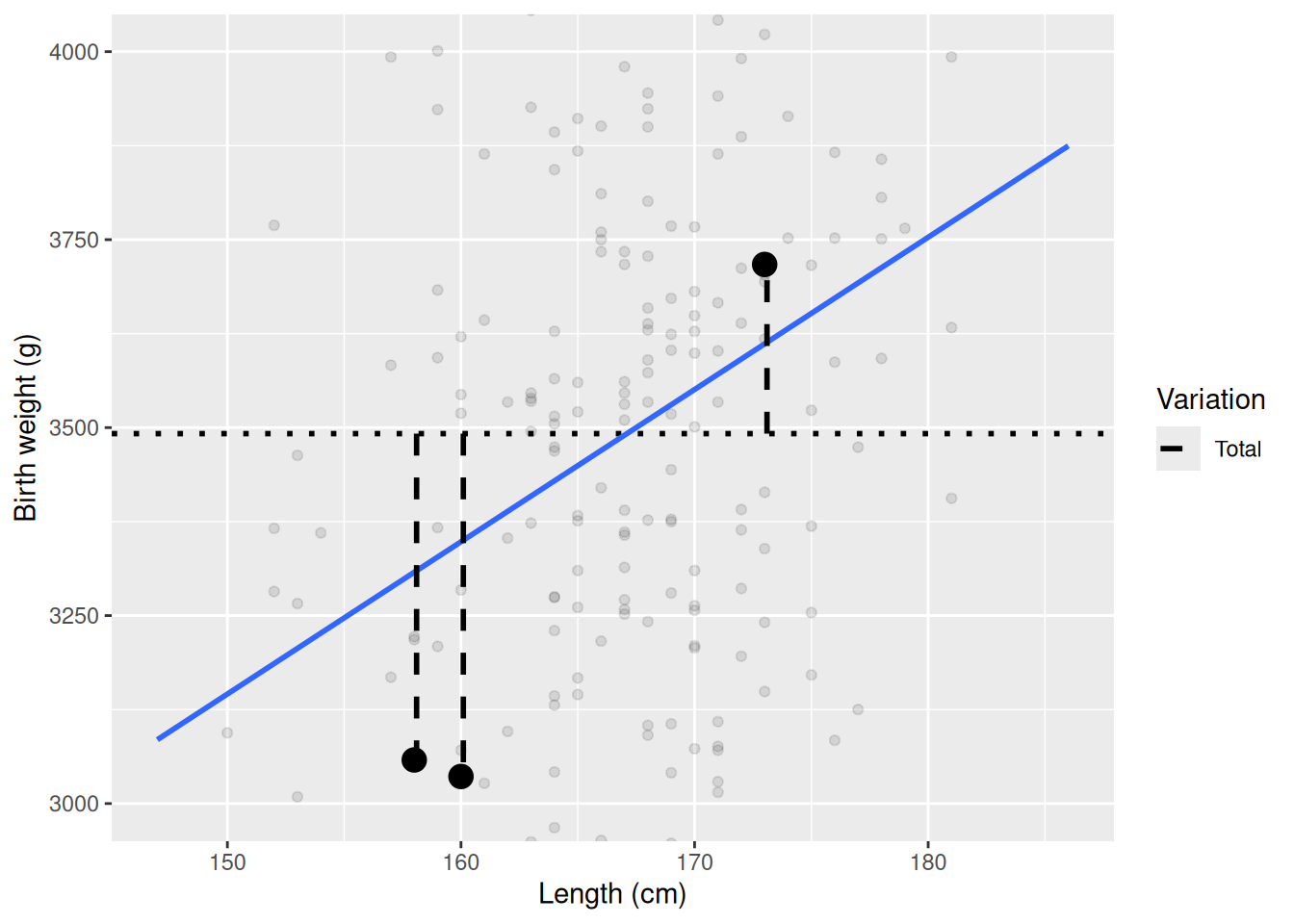
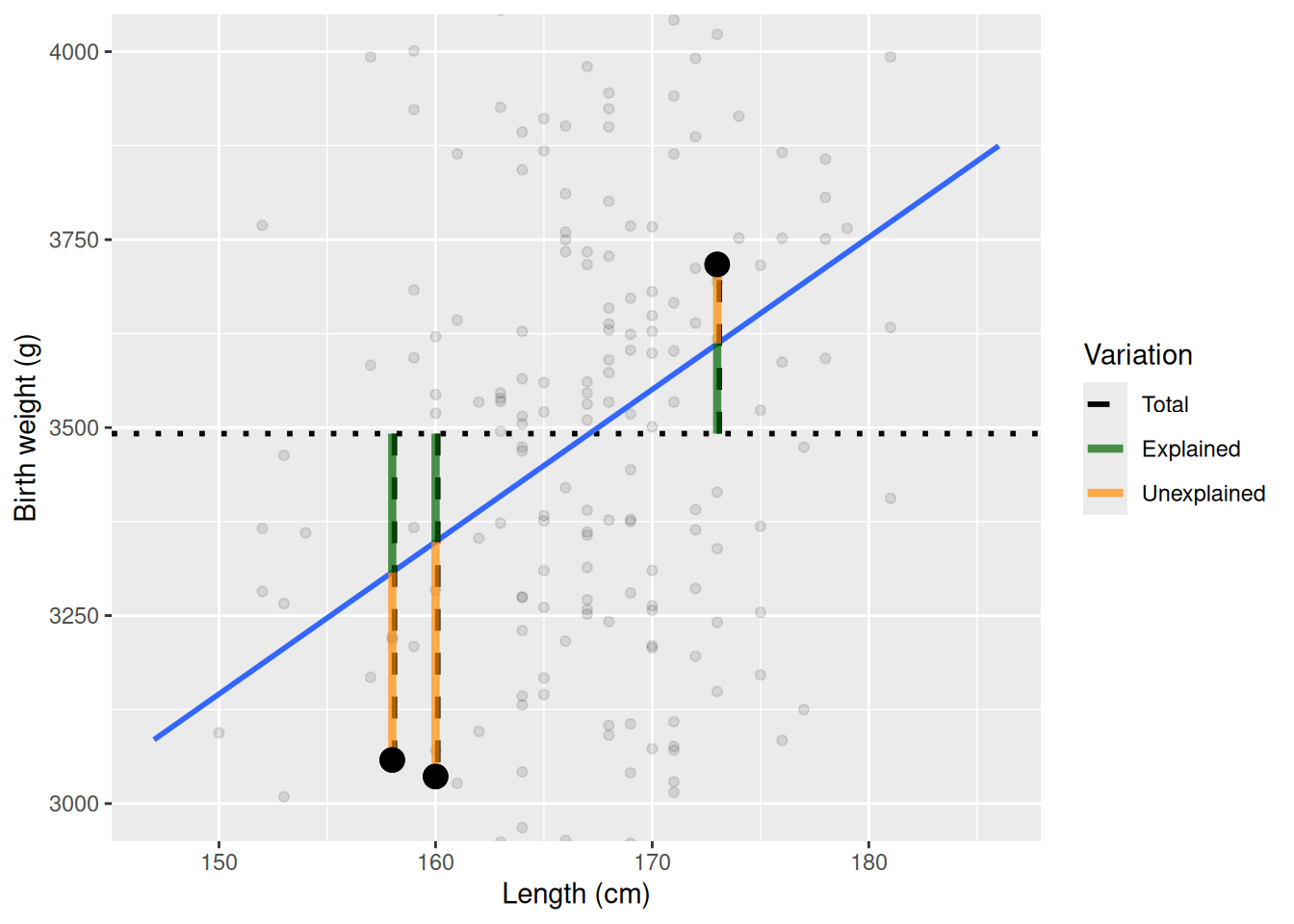
R\(^2\) can be interpreted as “the percentage of the variation in the outcome the model describes”. Specifically, it is the percentage of the variation around the mean of the outcome that the model describes. Let’s visualize this for a subset of the points for birth_weight_g ~ length_cm. Here we highlight three points, the mean value by a horizontal dotted line, and their total variation from the mean with vertical dashed lines.
We see the total variation as the distance from the mean value to the points in the y-direction. If all points align on the mean value, there is no variation to explain, but as long as there is some variation, it is possible that it can be explained by some other variable, in this case length_cm. If the regression line (in blue) would have been completely flat, length_cm wouldn’t have explained anything more that then mean of birth_weight_g. But how much of the variation does the regression line explain? We can illustrate this for the higlighted points by visualizing the distance from the mean to the regression line (explained variation) and from the prediction line to the observed value, i.e. the point (un-explained variation).
In this figure we see that part of the variation is explained by the line (green), but not all (orange). R\(^2\) is calculated by summing together the squared explained variation (green) and dividing by the squared total variation (dashed, black) for all points, mathematically R\(^2\) = \(\sum_{i}\) Explained\(_i^2\) / Total\(_i^2\), where \(i\) indicates each observation, i.e. each point. If the explained variation is the same as the total variation, R\(^2\) is 1 and the predictor explains 100% of the variation in the response (compare with the correlation). If the predictor doesn’t explain anything, i.e. the line is flat, R\(^2\) is 0. You are not expected to be able to calculate R\(^2\), as we will let lm do that for us, but you are expected to be able to interpret the value of R\(^2\).
For a more detailed explanation of R\(^2\), Wikipedia offers a good alternative with both visualizations and mathematical formulas.
7.2.3 Selecting between two simple linear regression models
Armed with R\(^2\) as a measure of how well a model describes the variation in the data, we can now compare the two models using either length_cm or weight_kg to explain the variation in birth_weight_g. It turns out that we have been calculating R\(^2\)-values with every lm call we have made, and we can see it by calling the summary function. We start by looking at the model of birth_weight_g ~ weight_kg.
Call:
lm(formula = birth_weight_g ~ weight_kg, data = birth)
Residuals:
Min 1Q Median 3Q Max
-1259.97 -270.84 2.46 296.60 1164.35
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2974.058 179.757 16.545 < 2e-16 ***
weight_kg 8.032 2.748 2.923 0.00382 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 458.4 on 228 degrees of freedom
Multiple R-squared: 0.03612, Adjusted R-squared: 0.03189
F-statistic: 8.543 on 1 and 228 DF, p-value: 0.003818
In the second line from the bottom we find “Multiple R-squared” and find that it is 0.03612. We can interpret this as “The weight of the mother explains 3.6% of the variation in birth weight of infants”. What about length_cm?
Call:
lm(formula = birth_weight_g ~ length_cm, data = birth)
Residuals:
Min 1Q Median 3Q Max
-1253.71 -291.45 39.43 274.12 1291.05
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 108.034 767.698 0.141 0.888
length_cm 20.251 4.591 4.411 1.59e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 448.1 on 228 degrees of freedom
Multiple R-squared: 0.07863, Adjusted R-squared: 0.07459
F-statistic: 19.46 on 1 and 228 DF, p-value: 1.585e-05
The mothers length explains a little bit more of the variation in infant birth weight, about 7.8%. For convenience, we may want to output only the R\(^2\) value from our regression. Again we can use the dollar operator.
These results may be underwhelming, as the predictors only explain a small percentage of the total variation. This motivates us to use multiple linear regression, capable of including multiple predictors at the same time to create models with more explanatory power than simple linear regression.
7.2.4 Exercises
What R\(^2\) value do you expect for the birth_weight_g ~ age model? Is it higher or lower than weight_kg or length_cm? Use summary to find out and confirm what you see by a scatter plot with a line using geom_smooth.
Fit a multiple linear regression model using formula = birth_weight_g ~ weight_kg + length_cm. Did R\(^2\) increase?
Run the following code (requires the plotly package) to create an interactive 3D visualization of birth_weight_g ~ weight_kg + weight_cm. Un-comment the three different “VIEW:” sections, one at a time, to view the plot from different angles. Try to understand how the surface represents multiple linear regression. Can you visualize more dimensions? Note: You don’t need to understand the code, rather try to understand the content. Hint: You may zoom in and out by scrolling while hoovering over the plot.
Code
#install.packages("plotly")library(plotly)# Fit the multiple linear regression modelmodel <- birth |>lm(formula = birth_weight_g ~ weight_kg + length_cm)# Create a grid of values for weight_kg and length_cmweight_kg_range <-seq(min(birth$weight_kg), max(birth$weight_kg), length.out =50)length_cm_range <-seq(min(birth$length_cm), max(birth$length_cm), length.out =50)grid <-expand.grid(weight_kg = weight_kg_range, length_cm = length_cm_range)# Predict birth_weight_g for the gridgrid$birth_weight_g <-predict(model, newdata = grid)# Create 3D scatter plotp <-plot_ly( birth, x =~length_cm, y =~weight_kg, z =~birth_weight_g, type ='scatter3d', mode ='markers', size =1)# Add regression surfacep <- p |>add_surface(x =~length_cm_range, y =~weight_kg_range, z =~matrix(grid$birth_weight_g, nrow =50), opacity =0.5)p <- p |>colorbar(title ="<b>Birth weight (g)</b>") |>layout(scene =list(xaxis =list(title="Weight (kg)"), yaxis =list(title="Length (cm)"),zaxis =list(title="Birth weight (g)")))# VIEW: birth_weight_g ~ length_cm perspective#p <- p |> # layout(scene = list(camera = list(eye = list(x = -2.25, y = 0, z = 0))))# VIEW: birth_weight_g ~ weight_kg perspective#p <- p |> # layout(scene = list(camera = list(eye = list(x = 0, y = 2.25, z = 0))))# VIEW: weight_kg ~ length_cm perspective#p <- p |> # layout(scene = list(camera = list(eye = list(x = 0, y = 0, z = 2.25))))# Show the plotp
7.3 Fitting multiple linear regression models
Now that we can compare models we are ready to jump into multiple linear regression. Fitting multiple linear regression models in R is hardly any more difficult than fitting simple linear models, just add more variables using the + sign in the formula. We start by adding all the variables to our dataset, including the categorical ’sex.
7.3.1 Naive approach
More predictors will explain more of the variation, so we start by naively using all possible predictors in our dataset. To include all variables except the outcome we can use dot, ., in the formula. It stands for “all variables in the data.frame except for the outcome”, which is perfect when we want to include all possible predictors.
model <- birth |>lm(formula = birth_weight_g ~ .)model |>summary()
Call:
lm(formula = birth_weight_g ~ ., data = birth)
Residuals:
Min 1Q Median 3Q Max
-986.78 -245.33 3.51 247.62 1101.82
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3507.946 4552.540 -0.771 0.44179
pregnancy_duration_wks 175.974 20.442 8.609 1.35e-15 ***
sexMale 152.066 50.903 2.987 0.00313 **
age 2.034 5.282 0.385 0.70050
length_cm -2.782 26.820 -0.104 0.91749
weight_kg 29.015 35.086 0.827 0.40914
bmi -66.988 96.855 -0.692 0.48989
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 378.1 on 223 degrees of freedom
Multiple R-squared: 0.3583, Adjusted R-squared: 0.3411
F-statistic: 20.76 on 6 and 223 DF, p-value: < 2.2e-16
We start by looking at R\(^2\) and see that it has improved a lot, now 35.8% percent of the variation in birth_weight_g is explained. But looking at the coefficient estimates and \(p\)-values (“Pr(>|t|)”) something seems off. The coefficients for length_cm and bmi are now negative, despite both being positive in their respective simple linear regressions, and length_cm and weight_kg are no longer significant. We have improved our R\(^2\), but sacrificed the interpretability of our model, we can no longer make any sense of it. Why does this happen? To answer that we need to better understand how adding more predictors to the model affects each predictor in the model.
7.3.2 Interpreting multiple linear regression
When we perform multiple linear regression the significance and coefficient estimate of each predictor is dependent on the other variables included in the model. This may change the coefficient estimates and \(p\)-values for a predictor when using it in a multiple linear regression model compared to a simple regression model. The hypotheses in multiple linear regression highlights this. For example, the hypotheses for the coefficient of length_cm in the model including all potential predictors are
\(H_0\): There is no linear relationship between the mothers length and the birth weight of the child, given that pregnancy duration, sex, mother age, weight, and BMI is also part of the model.
\(H_a\): There is a linear relationship between the mothers length and the birth weight of the child, given that pregnancy duration, …, and BMI are also part of the model.
Both the values of the coefficients and the \(p\)-values depend on the other variables included in the model. The interpretation of the coefficients follows the hypotheses in depending on the other variables in the model:
When the mothers length increases by 1 cm the birth weight of the child decreases by 2.782 grams on average, given that the other variables in the model are held fixed.
Looking at our model, this statement becomes an issue: BMI is a function of both weight and length, BMI = Weight / Length\(^2\). The interpretation of the coefficient for BMI is then
When the mothers BMI increases by 1 the birth weight decreases by $$67 g, given that the other variables in the model, including weight and length, are held fixed.
But this cannot be, as if length and weight are held fixed, BMI cannot change! The interpretation of the model breaks down when all three of these variables are included in the model, causing the un-intuitive \(p\) values and coefficient values. When the predictors are (strongly) correlated, as in this case with bmi, weight_kg, and length_cm, the model suffers from multicollinearity, invalidating the inference of the model, i.e. interpretation of coefficients and \(p\)-values.
7.3.2.1 Exercises
The code below simulates data for ice cream sales and snake bites during the summer months. Copy the code and visualize the relationship between ice_cream_sales and snake_bites (using geom_point and geom_smooth with method = "lm") and fit a linear regression model of ice_cream_sales ~ snake_bites. Do we have a linear relationship? Is it significant?
# Simulating dataset.seed(42) # Important to include this!n_days <-153n_years <-5# Daily observations stored as a decimal number of the monthmonth <-rep(seq(4, 8, length.out = n_days), n_years) ice_cream_sales <-2000+3000*sin(pi * month /14) +rnorm(length(month), 0, 200)snake_bites <-20*sin(pi * month /14) +rnorm(length(month), 0, 8)ice_cream <-tibble(month = month, ice_cream_sales = ice_cream_sales, snake_bites = snake_bites)
Would you recommend an ice cream company to increase snake bites in order to increase ice cream sales? In other words, do you think that the effect of snake bites on ice cream sales is a causal effect? Causal effect in this case means that if we increase the number of snake bites we will also increase the number of ice cream sales.
Now fit a model including month as well, i.e. ice_cream_sales ~ . and state the hypotheses for the coefficient for snake_bites. What changed? Is the coefficient for snake_bites still significantly different from 0 with significance level 0.05?
7.3.3 Multicollinearity
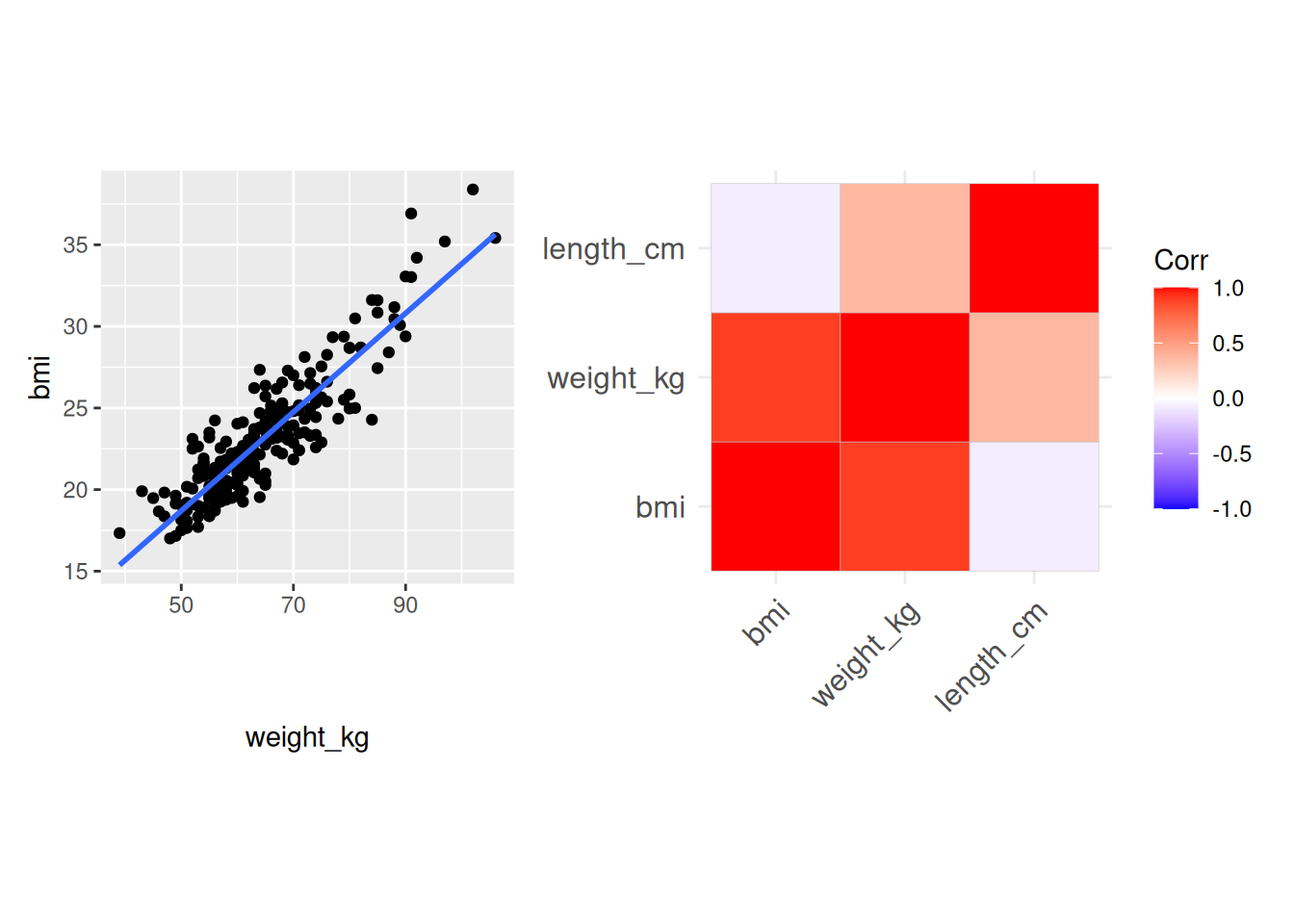
If the coefficients and \(p\)-values change drastically from simple linear regression models or from visualizations in scatter plots or correlation plots we should suspect multicollinearity in our model. It is also possible to look at the potential predictors in the dataset and their correlation in a scatter plot or in the correlation plot to try to anticipate multicollinearity.
We see a strong correlation between bmi and weight_kg and moderate correlation between weight_kg and length_cm. To assess multicollinearity in a multiple regression model we can use the Variance Inflation Factor (VIF) which can be calculated using the vif function from the car package.
library(car)vif(model)
pregnancy_duration_wks sex age
1.045718 1.039959 1.058718
length_cm weight_kg bmi
47.932159 239.468621 208.562969
VIF-values around 5 should alert you to potential issues with multicollinearity, and values above 10 suggest that the model suffers from multicollinearity. As we can see our model has VIF-values over 200 for weight_kg and bmi! In this scenario we have already understood why, because of the relationship between BMI and weight and length.
Fitting a model with all possible predictors improved our R\(^2\), but at the cost of interpretability. In addition to loosing interpretablility, a more complex model is more prone to overfitting to the data in the sample, leading to worse predictions about the population. Using our model to predict new, unobserved data points, i.e. birth weights in this example, is what we want to use the model for if we are interested in prediction. So even if we don’t care about the inference and the interpretability of the model, it may be a bad idea to include all variables. Instead we should do model selection, looking at several models with different predictors and different number of predictors to find a model that is both interpretable and offers good predictive power, i.e. high R\(^2\).
7.4 Model selection
To select a model that is both interpretable and useful for prediction is a difficult task, and a good quote to remember by statistician George Box is “All models are wrong, but some are useful”. When fitting models it is up to you to argue why the model is useful. Many times it is a good idea to use expert (domain) knowledge to motivate decisions in model selection. If you have access to knowledge about the data, either by your own reasoning, by knowledge about how the data was collected, or from an expert in the domain, you can include or excluding variables that you know are not useful. For example in the penguins dataset you may assume that the year the penguin was observed will not have an effect on the birth weight of the penguin. A reasonable assumption if we believe that the conditions haven’t changed from year to year. If you don’t have any background knowledge accessible there are systematic methods that allow us to select which variables to include.
7.4.1 Using domain knowledge
Returning to our birth weight model with all variables in the dataset as predictors, we will now try to simplify our model to increase interpretability. We learned before that the relationship between the outcome and a predictor may become insignificant when we include another variable in the model and that our model suffers from multicollinearity. We identified the problem as being the relationship between BMI, weight, and length. Since we know that a model including all of these variables cannot be interpreted, we may choose to create a model removing one of the variables. BMI is a good candidate, as it is strongly correlated with weight. To remove a variable from the model we can use dot again in combination with a minus sign, - to use all variables exceptbmi.
Call:
lm(formula = birth_weight_g ~ . - bmi, data = birth)
Residuals:
Min 1Q Median 3Q Max
-979.93 -247.04 1.17 244.13 1105.81
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -6573.071 1040.665 -6.316 1.43e-09 ***
pregnancy_duration_wks 176.335 20.411 8.639 1.08e-15 ***
sexMale 148.713 50.613 2.938 0.003646 **
age 2.241 5.267 0.425 0.670904
length_cm 15.535 4.232 3.671 0.000302 ***
weight_kg 4.807 2.435 1.974 0.049634 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 377.7 on 224 degrees of freedom
Multiple R-squared: 0.357, Adjusted R-squared: 0.3426
F-statistic: 24.87 on 5 and 224 DF, p-value: < 2.2e-16
vif(model_de)
pregnancy_duration_wks sex age
1.045037 1.030526 1.055327
length_cm weight_kg
1.196283 1.156474
Now we see that there is no problem with multicollinearity (lowest possible VIF is 1), all the coefficient estimates have the expected sign, and all relationships are statistically significant except for age. This means that age has no significant linear relationship with the outcome, given the other variables in the model, which is a good reason to remove it from the model.
Call:
lm(formula = birth_weight_g ~ . - bmi - age, data = birth)
Residuals:
Min 1Q Median 3Q Max
-1000.23 -249.24 -6.36 249.70 1102.63
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -6504.850 1026.365 -6.338 1.26e-09 ***
pregnancy_duration_wks 175.099 20.167 8.683 7.97e-16 ***
sexMale 149.730 50.465 2.967 0.003332 **
length_cm 15.842 4.163 3.806 0.000182 ***
weight_kg 4.800 2.431 1.975 0.049545 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 377 on 225 degrees of freedom
Multiple R-squared: 0.3564, Adjusted R-squared: 0.345
F-statistic: 31.15 on 4 and 225 DF, p-value: < 2.2e-16
After removing age we see that our R\(^2\) decreased, which will always be the case when removing a variable from the model, as all variables explain some of the variation in the outcome, but if the change in R\(^2\) is small there is a good chance that the variation the variable explains is only due to chance and may possibly lead to overfitting. In this case we can use “Adjusted R-squared”, adjusted R\(^2\) or R\(^2\)-adj, which we find next to “Multiple R-squared” in the summary output. It is based on R\(^2\), but gives a penalty for including more variables in the model in an attempt to promote smaller, more easily interpretable models. Comparing with the previous model the adjusted R\(^2\) has increased after removing age, indicating that age didn’t explain enough of the variation in birth_weight_g to warrant inclusion in the model. Adjusted R\(^2\) can be used to remove variables even if the variable has a significant relationship with the outcome, as this may happen when sample sizes are large, even if the predictor explains only a small part of the variation. In general, smaller models are easier to understand and should be preferred when not sacrificing much explanatory power, i.e. R\(^2\).
In our latest model all relationships are statistically significant and our final value of R-squared is 0.3564, compared to 0.3583 when including all variables in the dataset. In this case we almost didn’t lose any explanatory power while making our model more interpretable by reducing the number of variables, making sure the model doesn’t suffer from multicollinearity, and by only including statistically significant variables. Note that when reporting the final model we use to R\(^2\) and not the adjusted R\(^2\).
In this example we could use our knowledge of the relationship between BMI and weight to design a good model. If we don’t have knowledge about the variables we have to resort to systematic model selection strategies.
7.4.2 Using . in formula
When using . in the formula for fitting a regression model, lm implicitly includes all variables, including those removed by -. This has two implications: the model is trained (fitted) only on the observations where all the variables are complete, i.e. all rows with no missing values and, when the model is used, it expects a value for the removed variables as well, even if it doesn’t use them during the prediction (see below for prediction). This is good when comparing models, as it ensures that the same data is used for all possible models, but when fitting the final model it is better to not use . in your formula, as it ensures the model is fitted on as much data as possible.
This example illustrates how lm handles missing values when using the . and not. We use palmerpenguins because it contains missing values and output only the R\(^2\) from the summary to illustrate the difference between the models. Both models are modeling body_mass_g ~ flipper_length_mm, but use different data for fitting the model.
library(palmerpenguins)# Model fitted by using the dot operator in formulamodel_dot <- penguins |>lm(formula = body_mass_g ~ . - species - island - bill_length_mm - bill_depth_mm - sex - year)model_dot_summary <- model_dot |>summary()model_dot_summary$r.squared
[1] 0.7620922
# Model fitted by explicitly listing the predictormodel_no_dot <- penguins |>lm(formula = body_mass_g ~ flipper_length_mm)model_no_dot_summary <- model_no_dot |>summary()model_no_dot_summary$r.squared
[1] 0.7589925
We can recreate the R\(^2\) of model_dot using only flipper_length_mm as a predictor by dropping all the observations (rows) with missing values before fitting model_no_dot. The model is then fitted using the same data as for model_dot.
# Model fitted by explicitly listing the predictor, dropping missing values firstmodel_no_dot <- penguins |>drop_na() |>lm(formula = body_mass_g ~ flipper_length_mm)model_no_dot_summary <- model_no_dot |>summary()model_no_dot_summary$r.squared
[1] 0.7620922
When comparing models handling missing values explicitly or using the dot is good. When fitting your final model you should avoid using .. In these lecture notes we do not consider this as we are not intending to use our models for practical applications, but it is good to be aware of when applying lm.
7.4.3 Exercises
Visualize and fit a regression model of bmi ~ weight_kg and confirm the functional relationship, i.e. the linear relationship.
Run the code below. Why does the regression model fail? How can we fit a model with formula y ~ x?
Code
set.seed(42) # Setting seed for reproducibilityx <-seq(1, 100) +rnorm(100, 0, 2)y <-3* x +rnorm(100, 0, 2)z <-rep(NA, 100)df <-data.frame(x = x, y = y, z = z)df |>summary()model <- df |>lm(formula = y ~ . - z)
7.5 Model selection strategies
When selecting models without any previous knowledge about the variables we can resort to several different strategies. Below we describe the different strategies along with domain (expert) knowledge to give an overview of the different options.
Domain (expert) knowledge: If there is domain knowledge available about the variables it is a good idea to use it. Sometimes this is possible to deduce by reading about the dataset and how it was produced, or from previous experience, and in other cases it may be necessary to involve a real expert.
Forward selection: If domain knowledge is not accessible it is possible to perform simple linear regression with each of the variables in the dataset and then start by adding the one which results in the highest R\(^2\) (or some other measure of model fit). In the next step one more variable is added, one by one, and the variable that increases R\(^2\) the most is added. The process is continued until some stopping rule is satisfied. A good stopping rule is to add variables until R\(^2\) adjusted is no longer increased.
Backward selection: All variables in the dataset are used as predictors, then the one with highest \(p\)-value is removed and a new model is fitted. Then the process is repeated until all variables have sufficiently low \(p\)-values (below 0.05 or some other threshold).
Mixed selection: Starts with forward selection, but in each step variables with high \(p\)-values are removed according to some threshold (0.05).
In our previous example we started like in backward selection, fitting a model with all the variables (except the response) as predictors, then removed bmi based on a VIF analysis and domain knowledge, and then age based on the high \(p\)-value. There is no one way to arrive at a good model and you may combine the different approaches as long as you are transparent with how the model was selected. If you don’t have any domain knowledge then it is a good idea to resort to one of the above mentioned strategies. We will now redo the model selection using backward selection without using any domain knowledge and ignoring the high VIF values when selecting what predictors to remove.
7.5.1 Backward selection in the birth weight dataset
The first step of backward selection is fitting all variables (except outcome) as predictors, just as before.
Call:
lm(formula = birth_weight_g ~ . - length_cm - age, data = birth)
Residuals:
Min 1Q Median 3Q Max
-1005.24 -242.74 -3.17 254.24 1099.70
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3862.19 815.73 -4.735 3.88e-06 ***
pregnancy_duration_wks 174.88 20.14 8.681 8.05e-16 ***
sexMale 152.50 50.36 3.028 0.00275 **
weight_kg 25.79 5.07 5.086 7.68e-07 ***
bmi -58.12 15.00 -3.875 0.00014 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 376.6 on 225 degrees of freedom
Multiple R-squared: 0.3579, Adjusted R-squared: 0.3465
F-statistic: 31.35 on 4 and 225 DF, p-value: < 2.2e-16
We end up with a model with a significant relationship with all the predictors, but including both bmi and weight_kg makes the model harder to interpret as BMI depends on weight. The model also has slight multicollinearity issues, even if it is not as catastrophic as before, making the inference about the model less reliable.
vif(model_bs)
pregnancy_duration_wks sex weight_kg
1.023938 1.026370 5.041159
bmi
5.042461
Comparing with our previous model that achieved R\(^2 = 0.3564\), the backward selection model is slightly better with R\(^2 = 0.3579\). In this case we may prefer the first model as it is more interpretable at the cost of only a very small amount of explained variance.
7.5.2 Exercises
Perform forward selection on the birth dataset, stop when R\(^2\) adjusted is not increased any more. Which variable has the lowest \(p\)-value in the single regression models? Is this surprising? What is the final model? Feeling lazy? Just look at the solution.
Based on the results of exercise 1, would the result using mixed selection been any different?
Perform backward selection on the penguins dataset to find a model for predicting body_mass_g. Start by excluding year as we do not believe it to be relevant. Take multicollinearity into account and use reasoning and R\(^2\) adjusted to select between models. Hint 1: When using vif with categorical variables with more than three levels the output changes. Look under “GVIF” for continuous variables and categorical variables with only two levels, i.e. sex, and ignore multicollinearity for species and island. Hint 2: This is a difficult task and many models can be considered to be correct.
7.6 Prediction
Predicting using multiple linear regression models follows the same structure as in simple linear regression. The only difference is that we now need to provide a value for all the predictors in the model. We give an example using the model we found using backward selection in the previous section, predicting the birth weight of a female child born in week 40 with a mother that is 170 cm long, weighs 68 kg, and has a BMI of 24.
Note: The lm function in R is sometimes troublesome to work with. If we fit our model with the formula birth_weight_g ~ . - length_cm - age we still need to specify age and length_cm for our prediction. Instead fitting the model by adding all the included predictors allows us to make predictions using only the included variables. So when using our model for prediction, explicitly state the variables that are included in the model is better. Another option is to set the variables of length_cm and age to some arbitrary, but valid number.
# Setting length_cm and age to 0 and using previously fitted modelprediction <-predict( model_bs, data.frame(sex ="Female", pregnancy_duration_wks =40, weight_kg =68, bmi =24, length_cm =170, age =0))prediction
1
3491.656
# Refitting model with only included predictors in the formulamodel_bs2 <- birth |>lm(formula = birth_weight_g ~ pregnancy_duration_wks + sex + weight_kg + bmi)prediction2 <-predict( model_bs2, data.frame(sex ="Female", pregnancy_duration_wks =40, weight_kg =68, bmi =24))prediction2
1
3491.656
We see that the prediction turns out the same either way.
7.6.1 Exercises
Use the model we found using domain knowledge or forward selection and compare the prediction with the result of the backward selection model.
Make a prediction interval for the backward selection model and the model you compared to before. Is the predictions different if we take uncertainty into account? That is, does the intervals overlap? Hint: Add the argument interval = "prediction" to the predict call.
7.7 Summary
In this chapter we have looked at how to compare simple and multiple linear regression models using R\(^2\), the explained variance in the outcome. We have learned how to deal with multicollinearity and several strategies for systematic model selection, which we can use when no domain knowledge is available. Finally we looked at how to use the predict function for multiple linear regression models.
This chapter is quite substantial, but the most important takeaway is:
Building models is hard and there are many good models but even more bad models. Motivate your choice of model based on domain knowledge if possible and be transparent in how the model was selected.
As long as the reader is able to follow how you made your decisions when selecting your model you have done a good job.